실습으로 살펴봤던 GCN이 수행한 Task는 하나의 그래프 네트워크에서 각 노드의 Class를 맞추는 Node Classification Task였다. 이외에도 그래프를 재구성하여 missing edge를 찾는 link prediction Task / 그래프 자체의 클래스를 맞추는 Graph Classification Task 등이 있다. 요번에 살펴본 논문은 GNN 뿐 아니라 그 이전에 리뷰했던 오토인코더의 개념도 활용하여 Unsupervised하게 Graph Classification 문제를 해결할 수 있는 방법을 제안한다. 해당 논문의 저자는 존경스럽게도 DeepWALK를 쓴 분이다.

Graph Kernel
Deep Divergence Graph Kernel을 본격적으로 보기에 앞서 Graph Kernel이 무엇인지 알고 가자. 위키피디아에 의하면 그래프 커널은 쌍으로 이루어진 그래프들의 유사도를 비교하기 위한 inner product function이라고 한다. 그래프 커널은 1999년에 convolutional graph kernel이라는 컨셉으로 처음 등장한 아직은 어린(?) 이론이라고 볼 수 있는데, 논문을 읽어보려다가 전공 원서를 읽는 기분이 들어 우선 덮어 두었다.
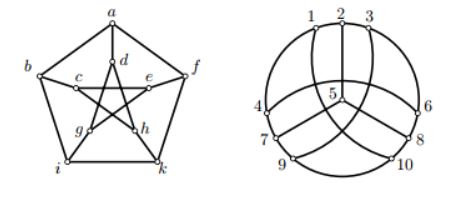
복잡한 식들을 보기에 앞서 유사한 그래프란 무엇인가에 대해 이해할 필요가 있다. 결론부터 말하자면 위 사진의 두 그래프는 유사하다. 정확히 말하면 두 그래프는 isomorphic하다. Graph Isomorpism이란 하나의 그래프에서의 연결관계를 어떤 함수를 통해 다른 그래프에서 똑같이 구현해 낼 수 있음을 말한다. 재미없게 말하자면 (x,y) is an edge of G1 iff (f(x),f(y)) is an edge of G2. Then f is an isomorphism, and G1 and G2 are called isomorphic 이라고 한다. 그런데 이 함수 f를 찾는 일은 NP-complete(아주 어려운 일)이다.
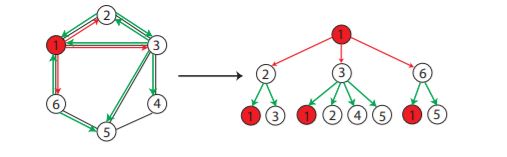
그리고 이런 복잡한 문제를 해결하기 위한 여러 kernel method들이 고안됬다. 딥러닝의 관점에서 두 그래프가 얼마나 Isomorphinc 한지 계산하고자 시도한 것이 해당 논문이라 볼 수 있다. 사실 논문의 여러 실험에서 비교 대상이 된 Weisfeiler-Lehman Kernel(2011)에 대해 리뷰해보려고 했는데, 쉽게 풀어놓은 리뷰도 별로 없고 논문의 무시무시함이 파괴적이라 구체적인 이해는 다음으로 미루고자 한다.
Novelty
• Deep Divergence Graph Kernels: A novel method for learning unsupervised representations of graphs and their nodes. Our kernel is learnable and does not depend on feature engineering or domain knowledge.
• Isomorphism Attention: A cross-graph attention mechanism to probabilisticly align representations of nodes between graph pairs. These attention networks allow for great interpretablity of graph structure and discoverablilty of similar substructures.
• Experimental results: We show that DDGK both encodes graph structure to distinguish families of graphs, and when used as features, the learned representations achieve competitive results on challenging graph classification problems like predicting the functional roles of proteins.
Deep Divergence Graph Kernels(DDGK)
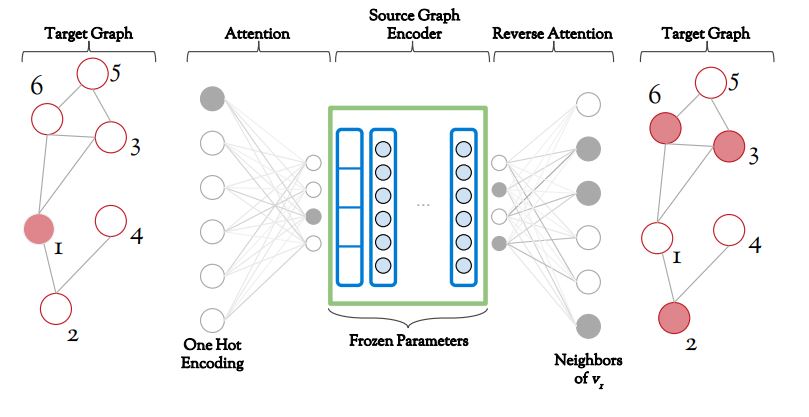
DDGK의 가장 핵심적인 컨셉은 Source Graph와 Target Graph를 분리하여 학습한다는 것이다.
모델의 부품들이 각각 어떤 역할을 하는지 이해하기 전에 모델에게 주어진 Task가 무엇인지 명확히 이해하고 넘어가는 것이 중요하다. DDGK의 목적은 우리가 알지 못하는 미지의 Target Graph가 미리 알고 있던 여러개의 Source Graph 중 어떤 것과 가장 유사한지 알아내는 것이다. DDGK의 학습 전략의 대전제는 오토인코더와 동일하다. “정상데이터에게는 그들만이 공유하는 패턴이 존재한다(Auto Encoder)” <-> “유사한 그래프들에게는 공유되는 구조가 존재한다(DDGK)” 특정 소스 그래프에 특화한 오토인코더가 존재할 때 해당 모델은 유사한 타겟 그래프에서도 좋은 Reconstruction을 수행할 것이라 믿는다.
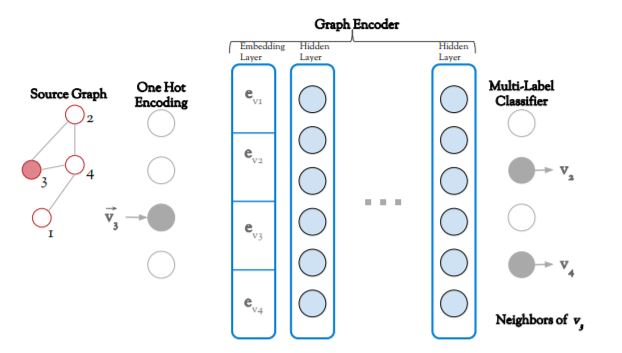
Source Graph Encoder
왼쪽부터 보는 것이 마음은 편하지만, 특이한 DDGK의 학습 방법 때문에 가장 먼저 보아야할 것은 전체 구조의 가운데에 존재하는 Source Graph Encoder 이다. 이름에서 유추할 수 있듯이 해당 모듈은 Input과 동일한 차원의 Dimension을 내뱉는 오토인코더의 형태를 하고 있다. 특이한 점은 Reconstruction의 목표가 되는 Output이 Input 그 자체가 아니라 Input에 연결된 다른 노드 정보라는 것이다. 즉, 위의 이미지의 그래프를 학습한다고 생각해봤을 때, 3번 노드의 값이 오토인코더에 input으로 들어갔을 때 edge가 연결되어있는 2와 4가 output으로 나오도록 학습될 것이다.
한글로 쓴 소스인코더 알고리즘
- 하나의 노드 값이 one-hot encoding 되어 input으로 들어간다.
- 해당 벡터는 임베딩 layer를 지나 d-dimension의 벡터로 변환된다.
- Graph Encoder의 마지막 layer는 input-dimension과 동일하다.
- 연결되어 있는 노드의 위치들이 높은 확률 값을 갖도록 모델이 학습된다.
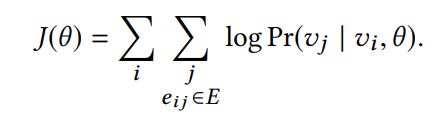
구체적으로 Maximize하고자 하는 목표가 되는 함수는 위와 같다. 논문에는 많은 노테이션이 등장하는데 아주아주 헷갈리기 때문에 여기서 분명히 외우고 넘어가자. v는 Source Graph의 노드이다! u는 Target Graph의 노드이다! e는 임베딩 함수이다! 우선 Source Graph Encoder에는 v와 e만 사용하여 학습이 진행된다. input이 v(i), output은 v(j). 다시 한 번 말하자면 i -> i를 reconstruction 일반적인 AE의 형태가 아닌 i와 연결되있는 여러개의 j(i -> j)를 reconstruction하는 것이 학습의 주요 목표이다.
Cross-Graph Attention
다음은 소스 인코더의 양 옆에 달려있는 Attention Network를 볼 것이다. 일반적으로 어텐션은 여러가지 정보를 Aggregate할 때 어떤 정보를 집중해서 봐야할지에 대한 선택을 위해 사용된다. 왼쪽의 Attention Network에서는 Source의 Node(v)가 Target의 어떤 Node(u)를 집중하여 Aggregate 할 것인지에 대한 가이드라인을 제시하기 위해 사용된다. 오른쪽의 인버스 어텐션 네트워크에서는 반대로 Node(u)가 어떤 Node(v) 를 집중할지를 선택하게 된다. 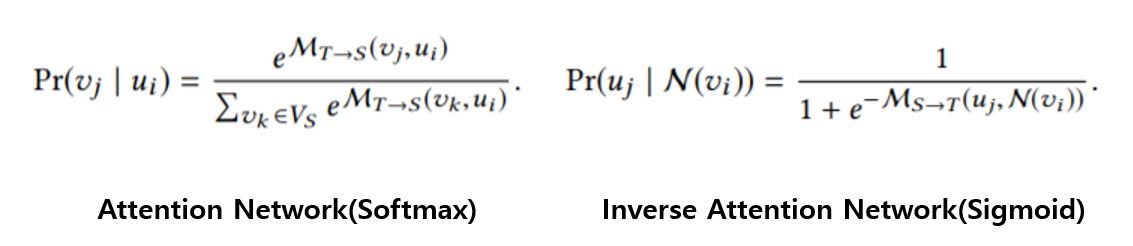
각 네트워크의 목적함수의 차이점을 이해하자. 주어진 Target Graph에 대한 Source Graph의 확률 분포는 softmax 형태를 띄고 있다. 합을 1로 강제하며 큰 값에 대해 더 강조하는 함수를 취했다는 것인데, 말 그대로 약한 surjection 꼴을 띄며 모델이 학습될 것이다. 우리가 일반적으로 알고 있는 어텐션의 꼴이라 볼 수 있다. 그러나 Inverse Network의 확률 분포는 전체 합을 1로 강제하지 않는 sigmoid 꼴임을 볼 수 있다. 위와 같은 형태를 통해 Source 그래프의 규모가 더 클 때에도 구조적인 제약에서 자유로울 수 있다고 한다.
위의 두 구조를 종합하여 DDGK의 학습전략을 이해해보자.
- Source Graph Encoder는 node 연결 관계를 잘 reconstruction하는 Encoder
- Attention Network는 소스와 타겟의 두 그래프의 노드를 잘 연결하는 모듈
타겟 네트워크는 소스 네트워크와 연결됨으로서 소스 네트워크의 Encoder를 사용할 수 있는 입장이 되었다. 두 그래프의 구조가 유사하다면, 소스 그래프가 Reconstrucion되는 형태가 타겟 그래프의 Reconstruction되는 형태가 유사할 것이다. 그렇다면 최종적으로 나온 Output이 타겟 그래프의 Input 노드와의 연결관계를 잘 표현할 것이다. 즉, DDGK가 소스와 타겟의 유사함을 스코어링하는 척도는 (input의 실제 연결 노드 vs ddgk를 통과해서 나온 노드) 가 될 것이다.
Attributes Consistency
위의 설명된 두 모듈은 두 그래프의 구조적인 유사함을 캡쳐하는 DDGK의 컨셉이라고 볼 수 있다. 지금부터 볼 것은 구조와는 상관없는 Node Feature / Edge Feature 등의 보조정보를 어떻게 모델에 녹여내어 학습할 것인가에 대한 전략으로 볼 수 있다.

사실 DDGK의 핵심적인 부분은 구조를 캡쳐하는 어텐션과 인코더에 있다고 개인적으로 생각한다. 위의 식이 의미하는 바를 컨셉적으로만 설명하자면, Attention을 학습하는 과정에서 구조적으로 유사한 후보 노드가 여러개가 존재할 수 있다. 따라서 구조 뿐만 아니라 Feature의 분포도 유사한 노드에 더 가중을 해줄 필요가 있다. 그렇다면 가중을 어떻게 해줄 것인가? 위에서 보다 싶이 로스 L은 Cross Entropy 꼴이다. 따라서 소스 노드와 타겟 노드의 분포가 동일하길 바란다. 즉, 여러 피쳐들에 대한 비율 값이 유사한 노드에게 더 큰 가중을 해줄 것이다.
Algorithm

알고리즘은 크게 세 부분으로 나눌 수 있다.
- 정보가 있는 N개의 소스 그래프 각각의 구조를 잘 캡쳐하는 N개의 소스 인코더를 학습한다.
- 각 타겟 그래프를 각 소스 그래프와 잘 매칭하는 N개의 어텐션 네트워크를 학습한다.
- M개의 타겟 그래프, N개의 소스 그래프 각각의 유사도를 스코어링 한 매트릭스를 얻는다.
Experiments
- Cross-Graph Attention
- Hierarchical Clustering
- Graph Classification
Cross-Graph Attention
첫 번째 실험은 Attributes Consistency, 즉 보조 정보가 추가됨에 따라 어텐션 네트워크가 어떻게 똑똑해지는지 확인해보는 것이다. 최근의 딥러닝 모델에서 어텐션이 많이 사용되는 이유는 강력한 성능도 있지만 아래와 같이 Weight 만으로 모델의 의사결정 과정을 유추할 수 있기 때문인 것 같다. 
- 왼쪽에서 오른쪽으로 갈수록 그래프의 보조 정보가 많아지고 있다.
- 위의 그래프가 Target, 아래의 그래프가 Source이다. 둘은 동일하다.
- Target에서 Source로 연결된 edge는 가장 weight가 큰 Attention을 뜻한다.
- 정보가 추가될수록 Attention Matrix가 diagonal 해진다.
- 즉, 정확한 매칭을 수행할 수 있다.
Hierarchical Clustering
두 번째 실험을 통해 DDGK가 여러 도메인의 그래프에 대해서 구별할 수 있는지 확인한다. 실험에는 3가지의 mutated graph와 3가지의 realistic graph가 들어간다. 여기서 mutated 그래프란 원래의 그래프에는 없던 노드를 추가하거나 edge를 삭제하는 등의 방식을 통해 가공된 sample이다.
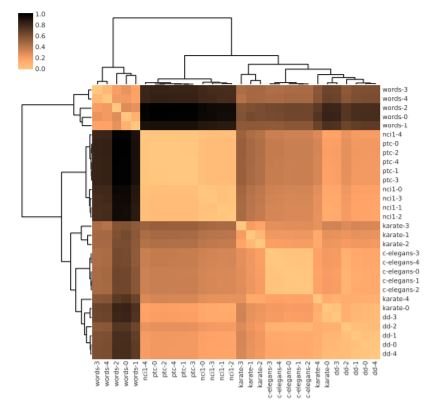
6개의 도메인에서 각각 5개의 그래프를 뽑아 30개의 그래프 셋을 설정한다. 각 그래프에 대해 소스 그래프 인코더를 생성하고 30*30의 Cross Attention 네트워크를 학습한다. 밝은 색깔일수록 Reconstruction Error가 낮은 것인데, 보다시피 같은 도메인에 속할수록 Error가 낮은 경향을 띄는 것을 볼 수 있다.
Graph Classification
마지막 실험은 그래프 분류 문제이다. 한 도메인의 여러 다른 그래프는 서로 다른 Label을 가지고 있다. DDGK는 라벨이 있는 그래프들을 소스 그래프로 학습하고, 라벨이 없는 그래프의 어텐션을 학습시킬 것이다. 그 후, 어떤 라벨군의 그래프에 가장 로스가 적은지를 바탕으로 분류를 수행할 것이다. 해당 실험에는 4가지 도메인의 그래프가 사용됬는데, 그 중 D&D 데이터 셋을 살펴보자.
D&D Dataset
Distinguishing enzyme structures from non-enzymes withou alignments(2003)
단백질이 효소인지 혹은 효소가 아니인지 구별하는 Task. 2003년에 SVM을 통해 77% accuracy를 얻은 Task이다. DDGK의 정확도는 83%. 생각보다 그렇게 큰 차이는 아니다. 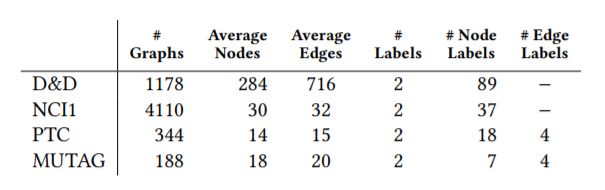
그래프에 관련한 논문들에는 위와 같이 각 그래프 도메인의 요약값을 기록해 놓는 경우가 많은 것 같다. D&D 데이터셋의 경우 총 1178개의 그래프로 이루어져있으며, 효소가 맞는지 아닌지를 구별하는 것이기 때문에 2개의 라벨로 나누어져 있다. 각 그래프는 평균적으로 284개의 노드와 716개의 Edge를 갖고 있으며, 특정 노드에는 아미노산 여부에 대한 라벨이 존재한다.
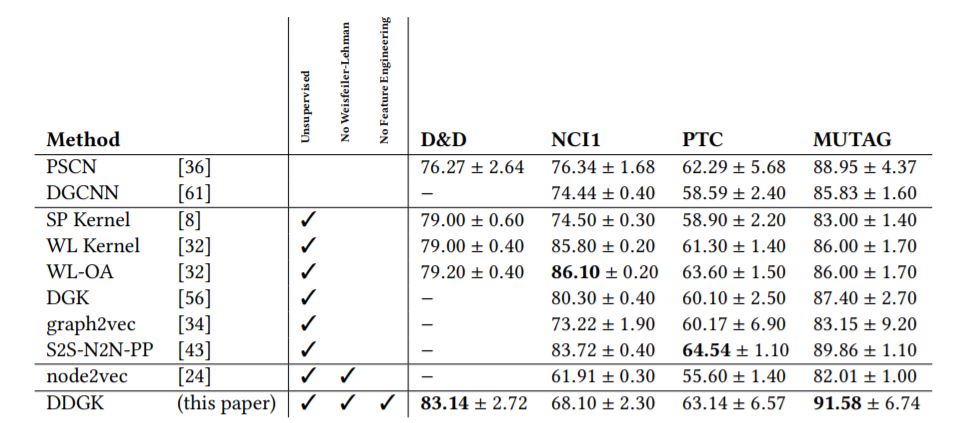
구체적인 학습전략은 역시 동일하다. N개의 소스 그래프에 대한 N x 1 로스 벡터가 M 개 얻어진다. 해당 벡터를 svm을 사용하여 최종적으로 그래프의 라벨을 분류한다. 놀랍지도 않지만 아주 성능이 좋다.
Conclusion
사실 그래프 커널에 대한 배경 지식 없이 Graph Classification 논문을 읽는 것이 매우 버겁게 느껴졌다. 아직 별로 고이지 않은 분야라 그럴까? 논문의 흐름이나 실험에서 주요 경쟁 대상은 WL - Graph Kernel이라는 다소 오래된(?) 기법이었다. 오토인코더에서 연결 정보를 Reconstruction 한다는 컨셉은 매우 흥미로웠다. 그런데 만약 소스 그래프의 라벨이 멍청했으면 어쩌지? 많은 클래스의 데이터 셋에서도 DDGK가 좋을까? 아쉽게도 논문의 모든 데이터셋은 BINARY 셋이었다.