컨셉을 이해하여 고개를 끄덕인 후, 그래서 어떻게 구현하지? 라고 생각해봤을 때 갑자기 멍해지는 기분에 불쾌한 경우가 자주 있다. 이론의 직관성과 멍함의 정도가 비례한다면 어텐션은 아주아주 기분 나쁜 개념이다. 어텐션은 대체 어떻게 구현하지?

Attention Network
우선 어텐션은 뭘까? 내가 이해한 어텐션의 컨셉은 집중이다. 많은 정보가 산재해있을 때, 무엇을 집중해서 볼지에 대한 것을 휴리스틱하지 않게 네트워크에 맡기자는 컨셉이라 볼 수 있다.
그렇다면 딥러닝에서 어텐션은 어떻게 쓰일까? 위의 사진은 시퀀스의 형태로 데이터의 정보가 전달되는 RNN 네트워크이다. 그런데 단순히 일방향으로 정보를 전달하는 것이 아니라 C(t) 라는 어텐션 벡터를 마지막 의사결정 직전에 첨가한다. 이미 네트워크를 흐르며 종합한 s ~ t 까지의 정보를 마지막 순간에 다시 한 번 취합한다. 논문을 읽지는 않았지만 네트워크를 흐르며 손실된 Long-Term Memory를 보존하고자 하는 의도였을 것 같다.
그럼 그냥 이전 네트워크에서 넘겨준 매트릭스를 남겨줬다가 나중에 어떤 계수를 곱해서 다시 더해주는 것일까? 그러면 Attention은 상수인가? 그럼 Set의 모든 데이터 각각의 특성을 어떻게 고려하지? 어떤 데이터는 t-1을 많이 집중해야되고, 어떤 데이터는 t-2를 집중해야하는데, 그런걸 어떻게 구현하지?
사실 어텐션을 어떻게 적용할지는 공식적으로 정해져 있는 것이 아니다. 모델의 구조나 목적하는 기능에 따라 여러가지 어텐션의 형태가 존재할 수 있는데, 오늘은 그 중 비교적 쉽고 직관적으로 구현해볼 수 있는 Graph Attention Netowrks를 구현해보자.
Graph Attention Networks (ICLR 2017)
2017년에 등장한 어텐션 논문을 한 편 구현해보자. 사실 Attention Is All You Need라는 어텐션 괴물 논문을 구현해보고 싶지만 어려워보이니깐 나중으로 미루기! 논문 리뷰가 아닌 코드 구현이 목적이기 때문에 실험이나 논리적 컨셉에 대한 것은 제쳐두자. 전체적인 알고리즘과 구체적인 어텐션에 집중하자.
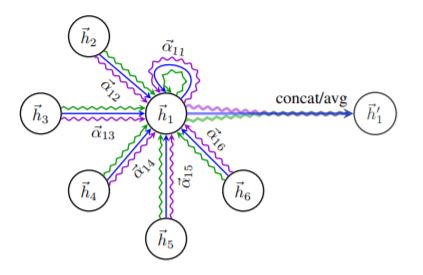
위의 이미지에 GAT의 모든 컨셉이 담겨져있다.
- h1은 주위의 다른 노드들에게 영향을 받아 h1’으로 진화한다.
- 어텐션을 h2,h3 … h6에게만 받는 것이 아니라 h1 자기 자신에게도 받는다.
- 어텐션이 파랑색, 보라색, 초록색 여러 가지 색깔로 표현되어 있다.
- convolution을 multi-channel로 하는 것과 같이 어텐션도 multi-head attention을 사용한다.
 위의 이미지로 GAT 네트워크를 구체적으로 이해할 수 있다.
위의 이미지로 GAT 네트워크를 구체적으로 이해할 수 있다.
Expression 1.
- e(ij) 는 i 노드와 j 노드의 Attention Coefficients
- 각 h(i), h(j) 앞에 붙어 있는 W는 F x F’ 크기의 매트릭스로 각 노드를 임베딩하는 매트릭스
- 각 노드는 F개의 피쳐가 있는데 임베딩을 통해 F’ Dimension으로 바뀌게 된다.
Expression 2.
- 분모의 N(i)는 i 노드에 연결된 이웃 노드들의 집합 (i 도 포함된다)
- 알파가 의미하는 것은 이웃들의 전체 coefficient 합 중 e(ij)가 차지하는 비율(혹은 확률)
Expression 3.
- 조금 더 구체적으로 Attention Coefficient가 어떻게 나타나는지 표현되어 있다.
- 식의 안쪽에서부터 살펴보면 [Wh(i) // Wh(j)]가 의미하는 것은 두 임베딩 벡터의 Concat이다.
- F’ + F’ 하여 2F’ 길이의 벡터를 single-layer로 forward 시킨다.
- LeakyRelu는 음수에 대해서도 어느정도 값을 취하는 nonlinear activation function
Expression 4.
- F 개 피쳐의 h는 주변 노드들의 (attention * F’) 들의 합인 h’로 재정의 된다.
Expression 5.
- GAT 에서는 concat 한 임베딩 벡터를 feed forward 하는 어텐션 네트워크를 K개 가진다.
- Attention Is All You Need (2017) 에서 제안된 multi-head attention mechanism
- F’ 길이의 벡터를 K번 Concat 하여 K * F’ 길이의 벡터를 얻는다.
Expression 6.
- 만약 h’ 뒤에 output을 위한 fc layer가 추가되는 것이 아닐 때 취하는 구조
- Expression 5와 같이 concat 하는 것이 아니라 K개의 F’ 길이 벡터들을 합해준 뒤 평균
여기까지 왔다면 GAT의 모든 것을 이해했다고 볼 수 있다. 사실 GAT의 가장 큰 장점은 모델의 간결함이라 생각이 든다. 어텐션, 임베딩, 그리고 예측 까지의 모든 과정이 사실은 모두 익숙한 FC - Layer의 일종일 뿐이다. 당시 이렇게 간단한 모델로 많은 Task에서 SOTA의 성능을 보였으니 모두가 어텐션에 열광할 수 밖에.
Deep Graph Library
본격적으로 GAT를 구현하기에 앞서, dgl 이라는 라이브러리를 하나 보고 가자. 이름에서 유추할 수 있듯이 Graph Neural Network를 구현하는데 도움을 주는 라이브러리인데, tensor 베이스의 Pytorch나 MXNet에서 사용 가능하다. 데이터 로드부터 네트워크 모듈까지 아주 다양한 기능을 제공하는 좋은 라이브러리인데 keras를 사용하는 것과 비슷한 이유에서 유용하다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
class GCN_layer(nn.Module):
def __init__(self, in_features, out_features, A):
super(GCN_layer, self).__init__()
self.in_features = in_features
self.out_features = out_features
self.A = A
self.fc = nn.Linear(in_features, out_features)
def forward(self, X):
return self.fc(torch.spmm(self.A, X))
# 이전에 GCN 네트워크를 Pytorch로 구현할 때
# 그래프 구조의 데이터를 취합하기 위하여 adjency matrix A를 생성했다.
# DGL이 있다면 이것을 아래와 같이 대체할 수 있다고 한다.
import dgl.function as fn
gcn_msg = fn.copy_src(src='h', out='m')
gcn_reduce = fn.sum(msg='m', out='h')
update_all(gcn_msg, gcn_reduce)
솔직히 아직 익숙하지가 않아서 하나 하나의 함수들이 뭘 뜻하는지는 잘 모르겠다. 우선 다양한 그래프들을 손쉽게 텐서 형태의 데이터로 로드할 수 있다는 장점만으로도 dgl이나 torch_gemetric과 같은 라이브러리와 친해질 필요가 있을 것 같다. 그럼 드디어 dgl을 사용하여 데이터를 로드하고 GAT를 구현해보자.
PyTorch implentation of the GAT
GAT의 기본적인 컨셉은 주변 노드의 정보를 어텐션으로 가중하여 현재 노드의 값을 얻는 것이다.
따라서 Node Classification을 위한 구조라 볼 수 있다. 지난번 구현했던 GCN에 사용한 Cora Dataset을 적용하는 것이 편하지만 똑같은 걸 또하면 재미 없으니깐. 오늘은 GAT 논문에서 실험 셋 중 하나였던 Citeseer Data Set을 가지고 실습을 진행하자.
Citeseer Data Set

1
2
# dgl library install
pip install dgl
기본적으로 모델링에 필요한 라이브러리들을 불러와주자
1
2
3
4
5
6
7
8
9
10
11
12
13
import time
import numpy as np
import torch
import torch.nn.functional as F
import torch.optim as optim
import torch.nn as nn
from dgl import DGLGraph
import dgl
from dgl.data import CitationGraphDataset
citeseer = CitationGraphDataset('citeseer')
이제 citeseer 데이터 셋을 불러올 건데 데이터 셋에 따라 import 해줘야하는 함수가 달라진다.
DGL Data Set 여기를 잘 참조해서 필요한 데이터를 불러오면 된다.
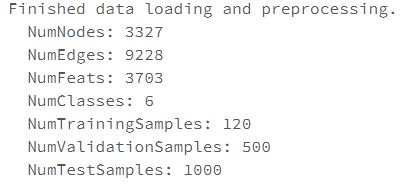
데이터를 다운로드하며 간단한 EDA 까지도 알아서 해준다.
DGL을 통해 불러온 데이터에 어떤 기능이 있는지 살펴보자.
1
2
3
4
5
6
7
8
9
dir(citeseer)
# networkx 라이브러리의 오브젝트인 그래프가 citeseer.graph 로 들어가 있다.
# draw 함수를 통해 아래와 같은 끔찍한 이미지를 만들어 낼 수 있다.
import networkx as nx
nx_G = citeseer.graph.to_undirected()
pos = nx.kamada_kawai_layout(nx_G)
display(nx.draw(nx_G, pos, with_labels=False, node_size = 0.01, node_color='#00b4d9'))

Citeseer Features
각 노드의 피쳐는 len(전체 노드 갯수)의 연결 된 엣지 정보가 담겨진 텐서이다.
데이터 셋은 다르지만 GAT - DGL Documentation를 참조하여 구현해보자.
코드 내에서의 설명은 위에 설명했던 Expression의 수식을 참조하며 진행해보자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
class GATLayer(nn.Module):
def __init__(self, g, in_dim, out_dim):
super(GATLayer, self).__init__()
self.g = g
# Expression 3
# F-Dimension의 피쳐 스페이스가 single fc-layer 지나며 F'-Dimension으로 임베딩
self.fc = nn.Linear(in_dim, out_dim, bias=False)
# i노드의 F' + j노드의 F' 길이의 벡터를 합쳐서 Attention Coefficient를 리턴
self.attn_fc = nn.Linear(2 * out_dim, 1, bias=False)
# Expression 3에서 어텐션으로 넘어온 값을 Leaky Relu 적용하는 Layer
# src는 source vertex, dst는 destination vertex의 약자
def edge_attention(self, edges):
z2 = torch.cat([edges.src['z'], edges.dst['z']], dim=1)
a = self.attn_fc(z2)
return {'e': F.leaky_relu(a)}
# dgl에서는 모든 노드에 함수를 병렬 적용 할 수 있는 update_all 이라는 api를 제공한다.
# 해당 api 사용을 위해 텐서를 흘려보내는 역할을 한다고 한다.
# 구체적인 update_all의 알고리즘은 잘 모르겠으니 그냥 input 함수라고 생각하자.
def message_func(self, edges):
return {'z': edges.src['z'], 'e': edges.data['e']}
# update_all에서는 흘려보내진 텐서를 각 노드의 mailbox라는 오브젝트에 저장하나 보다.
# 각 노드에는 여러 이웃이 있으니 mailbox에는 여러개의 attention coefficient가 있다.
# Expression 4에서 softmax 계수를 가중하여 element wise하게 합한다.
def reduce_func(self, nodes):
alpha = F.softmax(nodes.mailbox['e'], dim=1)
h = torch.sum(alpha * nodes.mailbox['z'], dim=1)
return {'h': h}
# (1) fc layer를 통해 피쳐를 임베딩
# (2) 그레프에 임베딩 된 벡터를 저장
# (3) apply_edges api를 모든 엣지에 적용하여 i - j 간의 attention coefficeint를 계산
# (4) 그래프에 저장된 z와e를 텐서로 reduce_func에 전달하여 새로운 h' 를 얻는다.
def forward(self, h):
z = self.fc(h)
self.g.ndata['z'] = z
self.g.apply_edges(self.edge_attention)
self.g.update_all(self.message_func, self.reduce_func)
return self.g.ndata.pop('h')
GAT에서는 2F’ 벡터를 Attention Coefficient로 연산하는 attc_fc layer를 여러개 적용하는 multi-head attention을 적용하여 평균 내어진 결과물을 최종 h’로 사용하였다. 간단히 생각해서 위의 GAT Layer를 따로 따로 여러개를 구하여 쌓은 다음 평균 낸 것이라 보면 된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
class MultiHeadGATLayer(nn.Module):
def __init__(self, g, in_dim, out_dim, num_heads, merge='cat'):
super(MultiHeadGATLayer, self).__init__()
self.heads = nn.ModuleList()
for i in range(num_heads):
self.heads.append(GATLayer(g, in_dim, out_dim))
self.merge = merge
def forward(self, h):
head_outs = [attn_head(h) for attn_head in self.heads]
if self.merge == 'cat':
# concat on the output feature dimension (dim=1)
return torch.cat(head_outs, dim=1)
else:
# merge using average
return torch.mean(torch.stack(head_outs))
Graph Neural Net의 기본적인 컨셉을 다시 한 번 생각해보자면, 이웃 노드들의 정보를 종합하여 새로운 나의 Feature로 사용하는 것이다. 따라서 Aggregate를 두 번 한다는 것은 2-hob 이웃들의 정보를, 세 번 한다는 것은 3-hob 이웃들의 정보를 모두 보겠다는 것이다. DGL - Document에서는 GAT Layer를 두 번 쌓아 2-hob 이웃 정보를 종합했다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
class GAT(nn.Module):
# 두 Layer의 인풋과 아웃풋이 다른 것을 볼 수 있다
# 원래 노드의 feature 개수가 F개라고 했을 때, layer를 한 번 지나며 F'개로 임베딩했다.
# 이것을 num_heads(attention 개수) 만큼 multi-head하게 보아 K*F' 길이로 cat했다.
# 두 번째 layer에서는 K를 1로 설정하여 single-head attention을 적용했다.
def __init__(self, g, in_dim, hidden_dim, out_dim, num_heads):
super(GAT, self).__init__()
self.layer1 = MultiHeadGATLayer(g, in_dim, hidden_dim, num_heads)
self.layer2 = MultiHeadGATLayer(g, hidden_dim * num_heads, out_dim, 1)
def forward(self, h):
h = self.layer1(h)
h = F.elu(h)
h = self.layer2(h)
return h
데이터를 함수에 넣을 수 있는 형태로 가공하자
1
2
3
4
5
6
7
8
9
10
11
12
13
def load_citeseer_data():
data = citeseer
features = torch.FloatTensor(data.features)
labels = torch.LongTensor(data.labels)
mask = torch.BoolTensor(data.train_mask)
g = data.graph
# add self loop
# GAT는 i <-> i의 self-attention도 종합하기 때문에 해당 정보를 edge에 추가해준다
g.remove_edges_from(nx.selfloop_edges(g))
g = DGLGraph(g)
g.add_edges(g.nodes(), g.nodes())
return g, features, labels, mask
데이터를 가져와서 모델을 학습하자
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
g, features, labels, mask = load_citeseer_data()
# create the model, 2 heads, each head has hidden size 8
net = GAT(g,
in_dim=features.size()[1],
hidden_dim=8,
out_dim=6,
num_heads=2)
# create optimizer
optimizer = torch.optim.Adam(net.parameters(), lr=1e-3)
# main loop
dur = []
for epoch in range(1000):
if epoch >= 3:
t0 = time.time()
logits = net(features)
logp = F.log_softmax(logits, 1)
loss = F.nll_loss(logp[mask], labels[mask])
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch >= 3:
dur.append(time.time() - t0)
if epoch % 100 == 0:
print("Epoch {:05d} | Loss {:.4f} | Time(s) {:.4f}".format(
epoch, loss.item(), np.mean(dur)))
로스가 줄어드는 것을 시각적으로 확인해보자.
1
2
3
import matplotlib.pyplot as plt
plt.plot(train_loss_arr)
display(plt.show())
오른쪽 이미지는 cora 데이터 셋에 대해 GCN과 GAT의 성능 차이를 비교한 문서에서 가져와봤다.

1
2
3
4
5
mask = torch.BoolTensor(data.test_mask)
pred = np.argmax(logp[mask].detach().numpy(), axis = 1)
answ = labels[mask].numpy()
np.sum([1 if pred[i] == answ[i] else 0 for i in range(len(pred))]) / len(pred) * 100
위의 코드를 통해 Test Set에 대한 분류 Accuracy를 계산할 수 있는데 58.4%가 나왔다.
끔찍한 결과에 뭔가 큰 잘못을 했나 고민했었는데
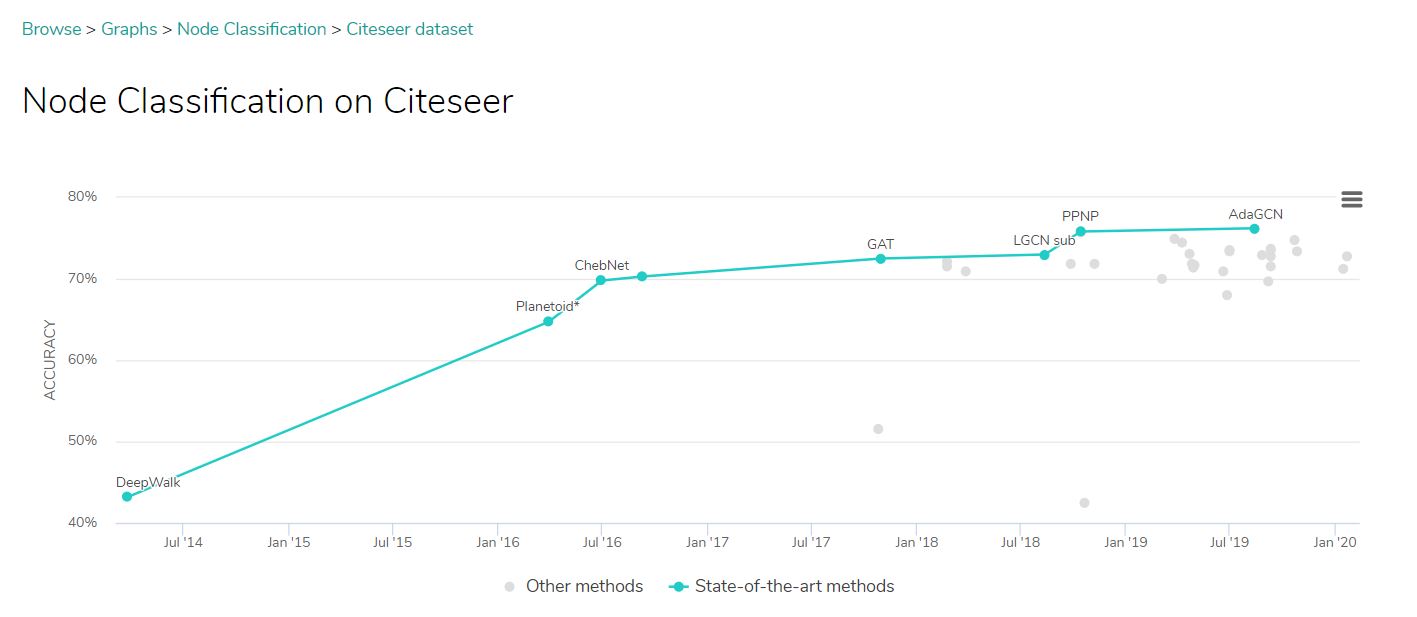
SOTA의 방법도 80%가 안되는 것을 보니 기본 GAT 구조로는 원래 이 정도 결과가 적당한가 보다.
기본적인 GCN에 이어 GAT을 가지고 Graph Node Classification Task를 수행해봤다. 요번에는 그래프 문제에 최적화하여 모델을 설계할 수 있는 DGL 라이브러리를 사용해서 구현해봤는데, 기회가 된다면 모델 학습 과정에서 병렬 처리를 위해 사용하는 여러 API들을 뜯어보는 것이 좋을 것 같다. 그리고 Document를 보면 모델의 구조와 hyper - paramter를 수정해가며 어떻게 더 좋은 결과물에 도달할 수 있는지에 대한 가이드도 제시하고 있으니 천천히 읽어보는 것을 추천한다.
끝