Dimensional Reduction
그저 데이터가 크고 복잡하면 도움이 될 것이라는 막연한 믿음은 사이비다. 단순히 처리가 힘들다는 문제 이외에도 데이터의 Sparse가 커지는 문제는 차원의 저주라는 그로스크한 이름으로 관찰의 대상이었다. 그리고 고차원의 데이터를 저차원으로 압축시켜 이런 문제를 해결하는 과제가 Dimensional Reduction Task이다.
차원 축소는 고전적으로 feature selection 과제와 동치로 여겨졌는데 Lasson Regression과 같은 것이 그 중 하나이다. 최근에는 일부를 고르는 것이 아니라 전부를 대표하는 저차원의 정보를 뽑는 컨셉의 Latent Feature Extraction이 많이 사용된다. 그리고 오늘은 그 중 딥러닝 모델에서 Latent Feature Extraction에 가장 범용적으로 사용되는 AutoEncoder를 구현해 보고자 한다.
PCA (Principal Component Analysis)
2차원 평면의 점들을 하나의 축에 사영한 후에, 그 축 위에서의 관계만을 보겠다는 것이 차원 축소의 개념이라 볼 수 있다. 오토인코더를 보기 전에 대표적인 Linear Latent Feature Extraction 기법인 PCA를 알고 가는 것이 좋을 것 같다. 한글로는 주성분분석이라 불리우는 PCA는 데이터를 잘 표현하는 ‘축’을 찾는 기법이다. 어렵게 말해보자면 mapping 이후 가장 큰 분산을 갖게 하는 unit vector 꼴의 orthogonal linear transformation을 찾는 기법이다.

PCA의 주어진 과제는 사영 후 분산을 최대화하는 w를 찾는 것인데 이것은 인풋 X의 Covariance Matrix의 가장 큰 eigenvalue의 eigenvetor를 찾는 일과 동치이다.
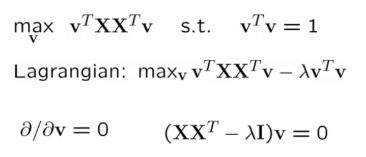
근데 이렇게 분산을 최대화하는 eigenvector를 찾는 과정은 쉽지 않은데 다행히도 수학적으로 분산을 최대화하는 Task는 error를 minimize하는 Task와 동치이다. 그리고 에러를 최소화하는 vector를 찾는 일을 딥러닝의 방식으로 해석한 것이 오토인코더라고 볼 수 있다.
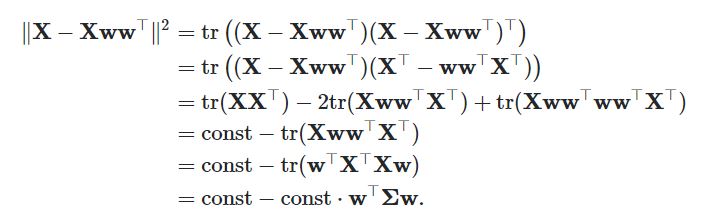
Auto Encoder
오토인코더는 Data를 가장 잘 재구성하도록 성장하는 모델이다. 커다란 숫자 덩어리가 여러 layer를 지나며 수많은 행렬곱에 의해 줄었다 늘어났음에도 원래의 숫자 덩어리 형태를 그대로 잘 유지할 수 있도록 모델은 학습된다.
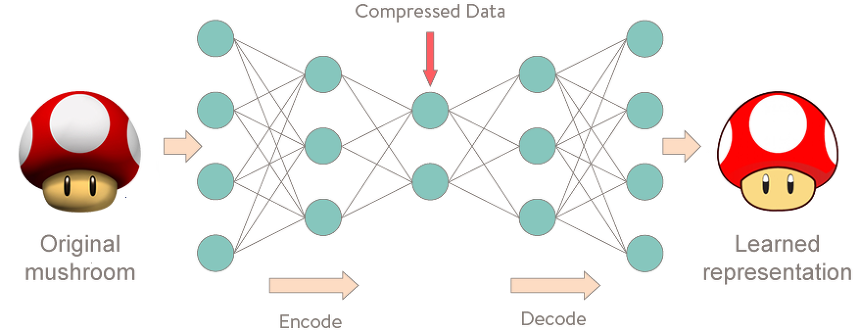
그런데 오토인코더는 왜 쓰는 것일까?
제목에도 써놓은 당연한 소리지만 오토인코더는 Dimensional Reduction의 용도로 가장 많이 쓰인다. 위의 사진과 같이 모델은 Encoder / Decoder 두 개의 네트워크로 구성된다. 그리고 그 사이에는 Input의 차원보다 적은 크기의 Layer가 존재하는데 이것을 Latent Feature Space라 볼 수 있다. Decoder 부분을 생각해보자. 모델은 낮은 차원의 벡터로 높은 차원의 벡터를 재구성(reconstruction)한다. Output이 Input과 동일하니 Latent Feature Space는 Input의 정보가 함축되어있는 공간이라 볼 수 있다. 즉, 모델의 Encoder 부분은 고차원의 데이터를 저차원으로 사영하는 Dimensional Reduction 네트워크인 것이다.
PCA는 Encoder 부분이 w이고 Decoder 부분이 그 역행렬인 가장 간단한 형태의 오토인코더 모델이라고 볼 수 있다. 그러나 네트워크의 Layer를 키우고 Activation이 행해지면 오토인코더는 더이상 PCA와 같이 선형적인 관계만을 보지 않는다. 정리하자면 오토인코더는 고차원 데이터의 Non Linear Dimensionality Reduction을 위해 사용된다.
그러면 오토인코더는 어디에 쓸 수 있을까?
가장 쉽게 오토인코더의 예제를 찾을 수 있는 것은 Anomaly Detection 분야이다. Anomal Data에 대한 가정은, Normal 데이터에 공통적으로 존재하는 feature가 그들에게 존재하지 않는다는 것이다.
예를 들어, 금융 거래 데이터를 가지고 금융 사기범과 일반인을 구별하는 과제가 있다고 생각해보자. 과거에는 이런 과제를 아주 휴리스틱한 룰 베이스의 시스템을 통해 수행해왔다. 골프장에서 거래내역이 있으면 일반인, 월급 통장이 있으면 정상인, 이런 규칙들을 정해놓고 O / X 로 분류를 수행했다. 이런 룰 하나 하나가 anomal 데이터에는 존재하지 않는 normal 데이터의 feature라 볼 수 있다.
이것을 오토인코더의 관점에서 생각해보자, 모델은 input을 잘 reconstuction 하는 방향으로 학습된다. 따라서 정상인의 데이터만으로 모델을 학습시킨다면 Encoder 네트워크는 Latent Vector Space에 정상 데이터의 공통적인 Feature들이 잘 함축되도록 업데이트 될 것이다. 그렇다면 학습이 완료된 모델에 anomal 데이터가 들어왔을 때, anomal 데이터에는 그런 Feature들이 없으니 재구성에 실패할 것이다.
정리하자면 오토인코더를 통한 Anomaly Detection의 학습 전략은 이렇다.
(1) Encoder - Decoder로 이루어진 네트워크를 설계한다
(2) 모델에 normal 데이터를 잔뜩 집어넣고 Reconstrucion Loss를 최소화하도록 업데이트한다
(3) 적절한 임계값을 설정하고 새로운 데이터의 에러가 임계값을 초과하면 Anomal Data로 분류한다
MNIST Aanomaly Detection
MNIST Database
0 ~ 9가 손글씨로 저장된 train 6만, test 1만 크기의 Database.
Experiment Setting
전체 숫자 중에 5와 나머지 숫자를 구별하고 싶다.
5가 Normal, 5를 제외한 나머지 숫자를 모두 Anomal로 정의하고 Anomaly Detection 과제를 수행한다.
Programming
Libraries
1
2
3
4
5
6
7
8
9
10
11
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
import torchvision.models as models
import numpy as np
from random import sample
import matplotlib.pyplot as plt
Handling
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
train_dataset = datasets.MNIST(root = './data', train = True, transform = transforms.ToTensor(), download = True)
test_dataset = datasets.MNIST(root = './data', train = False, transform = transforms.ToTensor())
total_dataset = torch.utils.data.ConcatDataset([train_dataset, test_dataset])
# 데이터 중에서 5인 것과 아닌 것을 구별하자
normal_dataset = sample([total_dataset.__getitem__(idx) for idx in range(len(total_dataset))
if total_dataset.__getitem__(idx)[1] == 5], 6000)
anomal_dataset = sample([total_dataset.__getitem__(idx) for idx in range(len(total_dataset))
if total_dataset.__getitem__(idx)[1] != 5], 1500)
# 모델을 학습할 때 완전히 5인 것만 학습하지 않고 다른 라벨도 조금 섞어줘서 semi-supervised하게 모델을 학습해주자
train_size, test_size = 5000, 500
train_dataset = normal_dataset[:train_size]
anomal_train = anomal_dataset[:test_size]
train_dataset.extend(anomal_train)
test_dataset = normal_dataset[train_size:]
anomal_test = anomal_dataset[test_size:]
test_dataset.extend(anomal_test)
batch_size = 512
train_loader = torch.utils.data.DataLoader(dataset = train_dataset, batch_size = batch_size, shuffle = True)
test_loader = torch.utils.data.DataLoader(dataset = test_dataset, batch_size = batch_size, shuffle = False)
Modeling
가장 기본적인 오토인코더는 단순히 멀티 레이어 퍼셉트론의 노드를 구조적으로 줄였다 늘린 것 뿐이지만 Denosing을 추가하거나 feature extraction을 convolution한 기법을 통해 수행하는 등의 여러 변형이 존재한다. 그 중 오늘 실습에서는 기본 버젼의 모델과 ConvAutoEncoder를 구현해본다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
class AutoEncoder(nn.Module):
def __init__(self, input_dim, hidden_dim1, hidden_dim2):
super(AutoEncoder, self).__init__()
self.encoder = nn.Sequential(
nn.Linear(input_dim, hidden_dim1),
nn.ReLU(),
nn.Linear(hidden_dim1, hidden_dim2),
nn.ReLU()
)
self.decoder = nn.Sequential(
nn.Linear(hidden_dim2, hidden_dim1),
nn.ReLU(),
nn.Linear(hidden_dim1, input_dim),
nn.ReLU()
)
def forward(self, x):
out = x.view(x.size(0), -1)
out = self.encoder(out)
out = self.decoder(out)
out = out.view(x.size())
return out
def get_codes(self, x):
return self.encoder(x)
class ConvAutoEncoder(nn.Module):
def __init__(self):
super(ConvAutoEncoder, self).__init__()
self.encoder = nn.Sequential(
nn.Conv2d(1, 3, kernel_size = 5),
nn.ReLU(),
nn.Conv2d(3, 5, kernel_size = 5),
nn.ReLU()
)
self.decoder = nn.Sequential(
nn.ConvTranspose2d(5, 3, kernel_size = 5),
nn.ReLU(),
nn.ConvTranspose2d(3, 1, kernel_size = 5),
nn.ReLU()
)
def forward(self, x):
out = self.encoder(x)
out = self.decoder(out)
return out
def get_codes(self, x):
return self.encoder(x)
여기서 get_codes 함수를 통해 Input의 Latent Vector를 추출할 수 있다.
ConvAutoEncoder에서는 padding 사이즈를 늘렸다 줄임으로서 Dimension을 조절할 수 있다.
Train - func
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
def train(model, Loss, optimizer, num_epochs):
train_loss_arr = []
test_loss_arr = []
best_test_loss = 99999999
early_stop, early_stop_max = 0., 3.
for epoch in range(num_epochs):
epoch_loss = 0.
for batch_X, _ in train_loader:
batch_X = batch_X.to(device)
optimizer.zero_grad()
# Forward Pass
model.train()
outputs = model(batch_X)
train_loss = Loss(outputs, batch_X)
epoch_loss += train_loss.data
# Backward and optimize
train_loss.backward()
optimizer.step()
train_loss_arr.append(epoch_loss / len(train_loader.dataset))
if epoch % 10 == 0:
model.eval()
test_loss = 0.
for batch_X, _ in test_loader:
batch_X = batch_X.to(device)
# Forward Pass
outputs = model(batch_X)
batch_loss = Loss(outputs, batch_X)
test_loss += batch_loss.data
test_loss = test_loss
test_loss_arr.append(test_loss)
if best_test_loss > test_loss:
best_test_loss = test_loss
early_stop = 0
print('Epoch [{}/{}], Train Loss: {:.4f}, Test Loss: {:.4f} *'.format(epoch, num_epochs, epoch_loss, test_loss))
else:
early_stop += 1
print('Epoch [{}/{}], Train Loss: {:.4f}, Test Loss: {:.4f}'.format(epoch, num_epochs, epoch_loss, test_loss))
if early_stop >= early_stop_max:
break
모델이 여러개니 학습 함수를 미리 설정해준다.
Validation Set은 따로 설정해주지 않고 test data에 대해서 early stop을 넣어준다.
결과물을 10 epoch을 수행할때마다 확인해주도록 하자.
Train - ing
배치 사이즈는 위에서 미리 설정해줬으니 이제 num_epochs, device, learning_rate 세 개만 설정해준다.
불행하게도 여기 환경에는 gpu가 없는 관계로 나의 device는 cpu가 된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
AE = AutoEncoder(28 * 28, 64, 32)
AE_loss = nn.MSELoss()
CAE = ConvAutoEncoder()
CAE_loss = nn.MSELoss()
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
AE = AE.to(device)
CAE = CAE.to(device)
learning_rate = 0.01
AE_optimizer = optim.Adam(AE.parameters(), lr=learning_rate)
CAE_optimizer = optim.Adam(CAE.parameters(), lr=learning_rate)
train(AE, AE_loss, AE_optimizer, num_epochs)
train(CAE, CAE_loss, CAE_optimizer, num_epochs)
Result
모델이 숫자 5의 feature extraction과 reconstrucion을 잘하도록 학습됬으니
이제 모델에 5를 넣었을때는 error가 적고, 5가 아닌 숫자를 넣었을때는 error가 클 것이라 기대할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
AE_normal,AE_anomal = [], []
CAE_normal,CAE_anomal = [], []
for X, _ in normal_train:
X = X.to(device)
# Forward Pass
AE_output = AE(X)
CAE_output = CAE(X.view((1,1,28,28)))
if _ == 5:
AE_normal.append(AE_loss(AE_output, X).item())
CAE_normal.append(CAE_loss(CAE_output.view(1,28,28), X).item())
else:
AE_anomal.append(AE_loss(AE_output, X).item())
CAE_anomal.append(CAE_loss(CAE_output.view(1,28,28), X).item())
Loss에 대한 히스토그램과 Confusion Matrix를 만드는 함수는 따로 첨부하지 않는다.
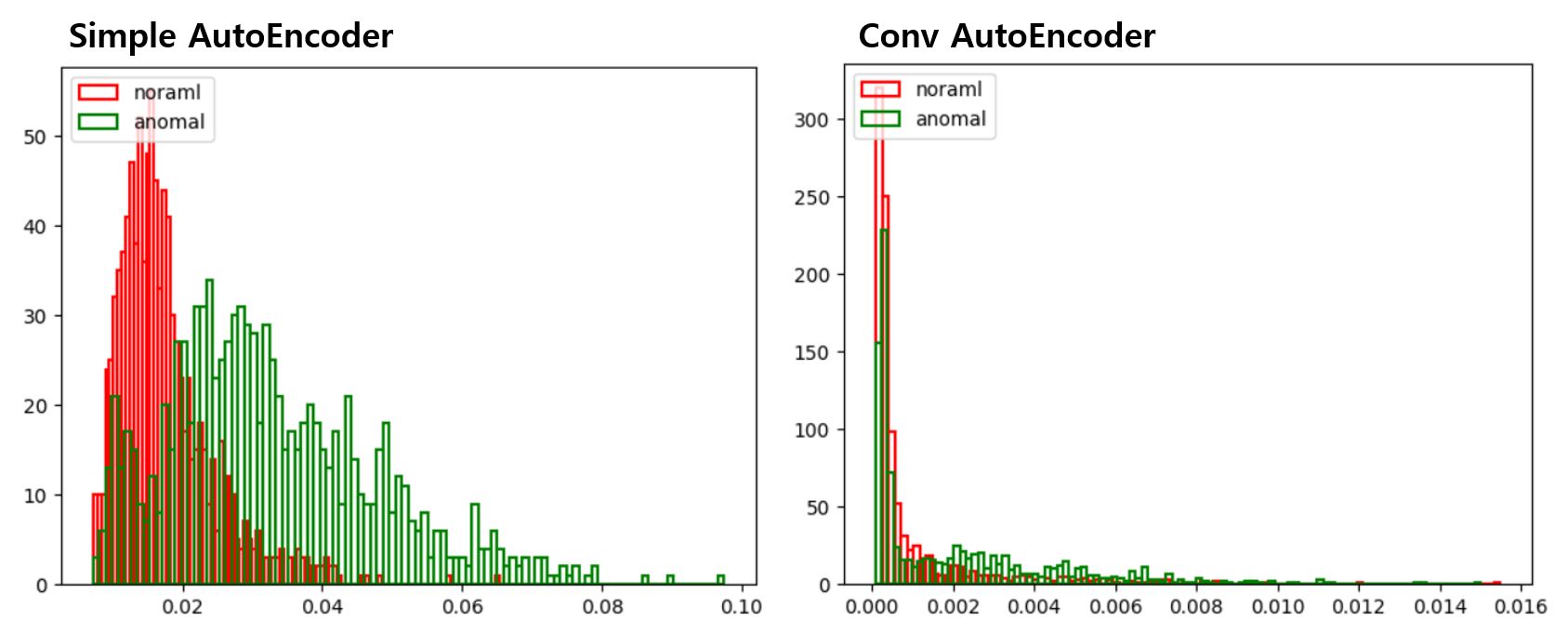
재밌게도 noraml과 anomal의 Reconstrucion Error 자체는 convAutoEncoder가 월등히 우월했지만
너무 잘하는 탓일까 anomal을 구분할 수 있는 명확한 threshold를 설정하는 일이 쉽지 않다.
AE의 threshold를 0.02로, CAE의 threshold를 0.002로 설정한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
y_true = []
AE_y_pred, CAE_y_pred = [],[]
for X, _ in normal_test:
X = X.to(device)
# Forward Pass
AE_output, CAE_output = AE(X), CAE(X.view((1,1,28,28)))
if _ == 5: y_true.append(1)
else: y_true.append(0)
if AE_loss(AE_output, X).item() < 0.02: AE_y_pred.append(1)
else: AE_y_pred.append(0)
if CAE_loss(CAE_output.view(1,28,28), X).item() < 0.002: CAE_y_pred.append(1)
else: CAE_y_pred.append(0)
임계값에 따라 정상1, 이상0으로 구별하여 Confusion Matrix를 그려보고 F1 Score도 구해본다
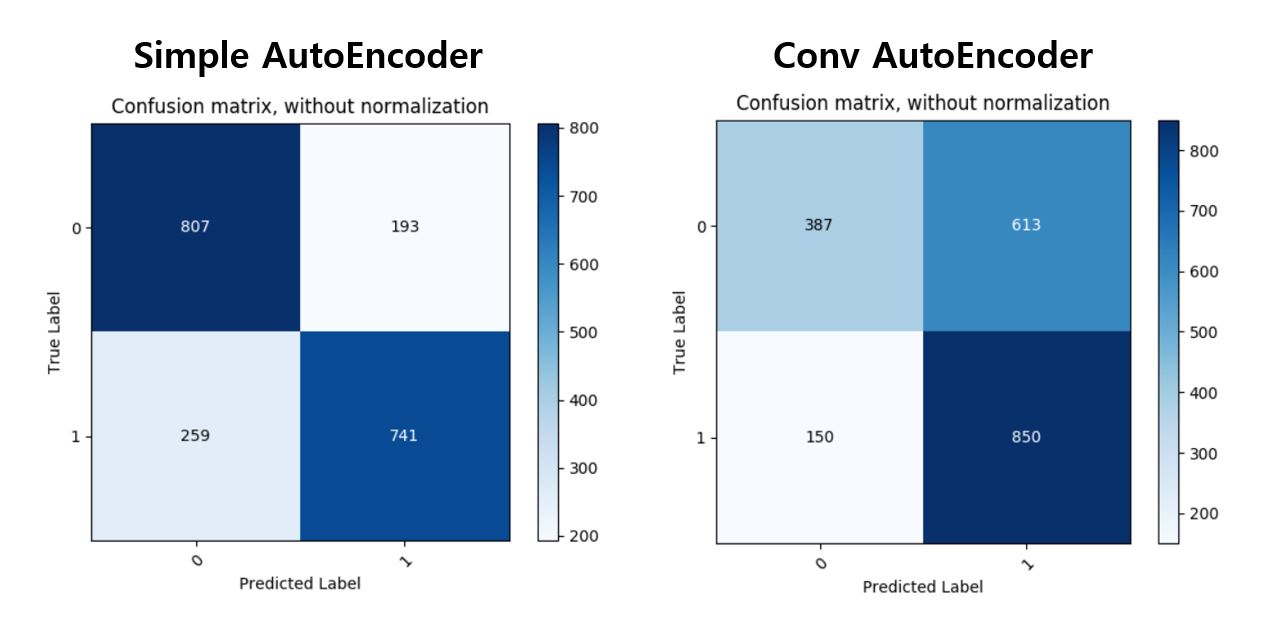
임계값을 어떻게 조정해주느냐에 따라 성능의 향상이 조금은 더 있겠지만 무의미하니 패스하고
최종적으로 AE의 F1 Score는 0.76, CAE는 0.69로 나왔다. 이런 결과의 이유를 조금 생각해보자면, 5라는 숫자가 0~9의 feature들을 조금씩 뭔가 다 포함하고 있어서 feature extraction에 너무 우수한 CAE가 5가 아닌 숫자에 대해서도 학습 과정에 Feature들을 다 파악해버린 것 아닌가 싶다. 그래서 이 다음에는 5가 아니라 1을 Normal로 정의하고 똑같은 방법으로 실험을 해보았다.
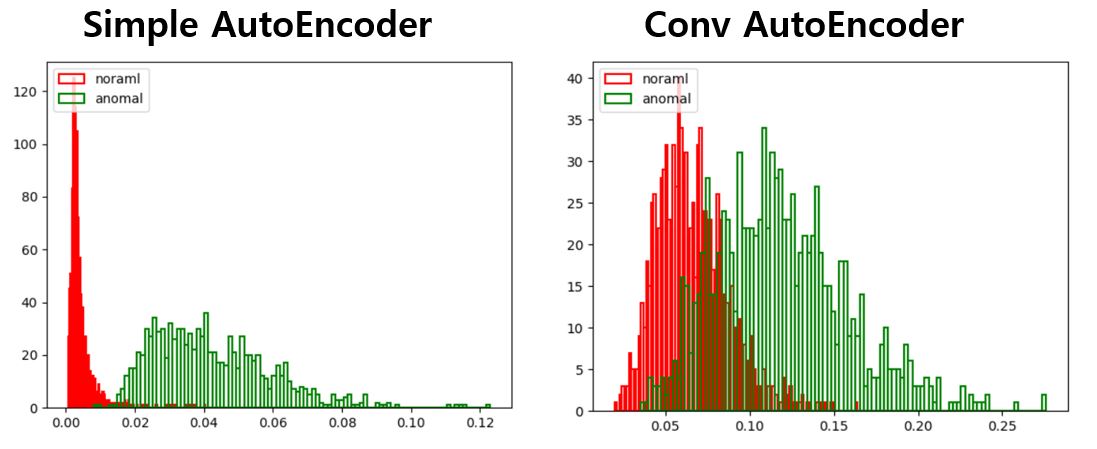
AE가 끝내주는 분류 성능을 보여줬다. (F1 score 0.96)
그리고 CAE는 Classfication에서도 Reconstrucion에서도 갑자기 AE에 대비하여 당황스러울 정도로 멍청해졌는데 1에는 feature라 할만한 특이점이 별로 없어서가 아닐까 추측해본다.
끝