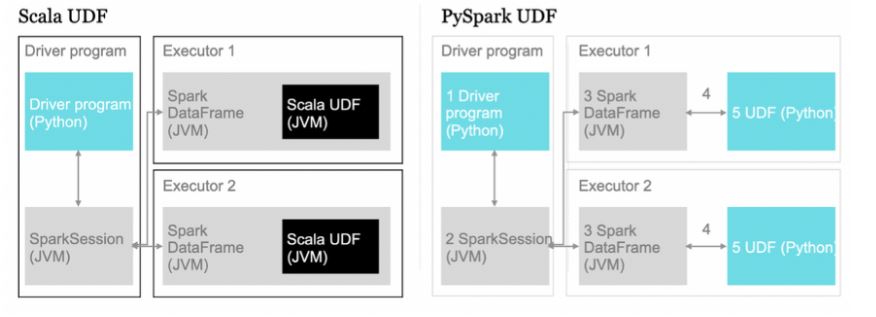
PySpark에서 복잡한 연산을 수행하기 위해 pandas udf를 사용하는 것에 대하여 포스팅을 한적이 있습니다. 그런데 최근(?)에 Spark 3.x이 나오면서 pandas udf를 사용하는 문법이 다소 바뀌었습니다. 아직은 Databricks에서 Spark 2.x대를 AS해주기 때문에 당장에 문제가 되는 부분은 없습니다. 그러나 버젼이 바뀜에 따라 코드를 수정해줘야하는 관리 포인트가 된 것은 맞습니다. 따라서 계속해서 pandas udf를 사용하는 대신에 spark의 native 언어인 scala를 사용하여 기존 udf 알고리즘을 대체하는 작업을 진행했습니다. 요번 포스팅에서는 scala udf의 사용 방법을 간단하게 살펴보도록 하겠습니다.
참조
python으로 쓰여진 UDF를 사용하기 위해서는 데이터를 “번역”해주는 과정이 필요합니다. scala 자료구조의 데이터를 python이 읽을 수 있는 형태로 변환해주고, 알고리즘이 끝난다음 scala로 다시 변환해줘야 합니다. 이런 작업을 seriallization/de-seriallization이라고 부르는데요,What, Why and How of (De)Serialization in Python ← 여기서 아주 쉽게 설명해주셨습니다.
udf 좀 쓰자고 scala를 맨땅부터 배우는 건 너무 무섭습니다. scala를 검색하면 함수형 프로그래밍 언어라는 말이 가장 먼저 등장하는데요, 어떻게든 돌아가는 함수 몇 개 만들어보는 것을 요번 포스팅의 목적으로 하겠습니다. 무슨 함수를 만들면 좋을까 싶은데요, PySpark에서 지원해주지 않는 것들이 좋을 것 같습니다.
목차
- Array Column min-max scale 해주기
- Array of Struct Column 특정 필드값을 기준으로 정렬 해주기
- String Column 에서 가장 많이 등장하는 단어 찾기
데이터

데이터는 제가 최근 쳐물려있는 주식의 (종목 코드, 최근 5일 시세, 기업 개요) 로 하도록 하겠습니다.
0. Scala 함수 미리 등록해주기
pyspark에서 scala로 쓰여진 함수를 사용할 것이기 때문에, python 배치 노트북을 돌리기 전에 scala udf를 미리 등록하는 작업이 필요합니다. 함수를 등록하는 방법은 udf를 jar 파일로 만들어서 pyspark session에 등록시키는 것이 일반적이지만, SQL 함수로 등록하는 방법이 저는 조금 더 직관적인 것 같습니다.
scala 노트북 (노트북 이름 = scalaUdf)
1
2
3
val lower: String => String = _.toLowerCase
sqlContext.udf.register("lower", lower)
python 노트북
1
%run ./scalaUdf
같은 폴더에 scala 함수를 등록하는 코드가 담긴 노트북을 작성합니다.
python에서는 해당 노트북을 실행시켜주는 코드를 먼저 돌려줍니다.

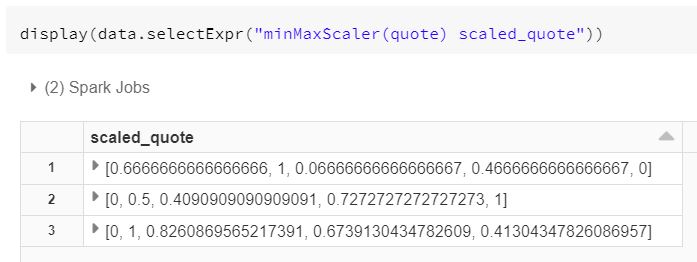
1. Array Column min-max Scale 해주기
최근 5일 시세를 min max scale 해주도록 하겠습니다. 의미는 없습니다. 진정한 max는 지금부터니깐..
scala의 경우에는 python과 마찬가지로 input의 타입을 꼭 미리 정해줄 필요는 없다고 합니다.
그래도 써주는 것이 좋을 것 같습니다. scala에서 quote 컬럼의 type은 Seq[Double]라고 하면 됩니다.
함수의 Output 도 0~1의 값이 나올 것이니 마찬가지로 Seq[Double]이 됩니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
// 함수명은 minMaxScale이라 정직하게 짓겠습니다.
def minMaxScaler(Inp: Seq[Long]): Seq[Double] = {
// pyspark에서 Array 타입이라고 되어있는 것은 scala에서 Seq라고 보면 됩니다.
var max_Inp = Inp.max
var min_Inp = Inp.min
if (max_Inp = min_Inp) {
// Array의 모든 값이 동일하다면 같은 길이의 0 Array를 return 합니다.
Array.fill(Inp.size)(0)
} else {
// 멍청한 방법인지는 잘 모르겠지만, 우선 분자 부분의 (v - min)을 해주고
// 이후에 그 값들을 (max - min) 값으로 나눠줍니다.
Inp.map(_ - min_Inp).map(_.toFloat / (max_Inp - min_Inp))
}
}
sqlContext.udf.register("minMaxScaler", minMaxScaler)
scala는 함수의 마지막 표현이 곧 리턴하고 싶은 값을 의미합니다.
2. Array of Struct 컬럼에서 특정 필드값으로 정렬해주기
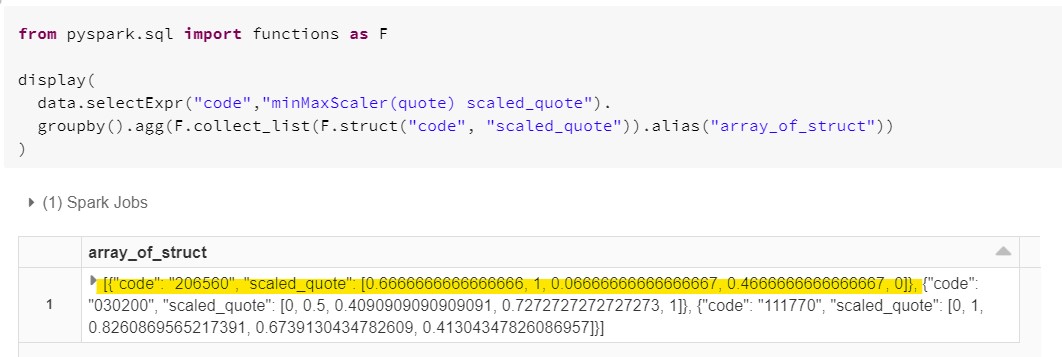
저는 지금 array_of_struct 라는 이름의 컬럼을 하나 만들어주었습니다.
(1) 각 주식의 종목 코드와 스케일 한 가격을 Struct로 묶어준 뒤
(2) 하나의 Array로 만들어주는 작업을 해주었습니다.
이제 하고 싶은 것은 종목 코드를 기준으로 저 Array를 정렬해주는 것입니다.
1
2
3
4
5
6
def sortByCode(Inp: Seq[Row]) = {
// scala에서 Row는 fields들의 collection을 의미합니다. (그냥 struct라고 봐도 될까?)
}