
Apache Spark is an Java Virtual Machine-based open-source
distributed general-purpose cluster-computing framework
Apache Spark는 머신 러닝 프로젝트 수행을 위한 MLlib, 데이터 스트리밍을 위한 Spark Streaming, 그래프 처리를 위한 GraphX 등의 라이브러리등을 지원한다. 대표적인 프로젝트들이 가진 색깔만 보더라도 스파크가 어떤 취지로 개발되어 어떻게 활용되는지 추측할 수 있다. 스파크에 대한 글들을 보면 하둡보다 메모리에서 100배 빠르다! 와 같은 말들을 볼 수 있는데, 이는 스파크만의 아주 고급진 directed acyclic graph (DAG) data processing engine에서 비롯된다고 한다. 사실 이게 뭔지는 읽어도 잘 모르겠지만 혹시 궁금하시다면 여기를 보면 좋을 것 같다.
스파크란 무엇인가! 스파크의 모든 것! 같은 글을 작성할 능력은 없고, 직접 사용해보면서 유용하다고 느꼈던 기능들을 정리해보면 좋을 듯 싶어 포스팅을 시작한다. 오늘은 스파크에서 사용자 정의 함수(User Defined Function)를 사용하는 법, 그 중에서도 pandas UDF를 사용하는 법을 정리해본다.
PySpark
기본적으로 Spark의 native langauge인 Scala로 프로그래밍하는 것이 정석이겠지만, 늘 그렇듯 나중의 숙제로 미루고 익숙한 파이썬으로 스파크를 사용한다. PySpark는 스파크 사용을 위한 Python API로 마치 pandas를 사용하는 기분으로 스파크를 사용할 수 있도록 도와준다.
업무적으로 스파크는 Validate 되어 있는 로그들을 가공하여 요약하는 배치 잡을 만들거나, 간단한 EDA 수준으로 데이터를 살펴보는 용도로 사용하고 있다. 물론 스파크에서 기본적으로 제공하는 함수들만으로도 대부분의 요구사항을 수행하기 충분하지만, 가끔 복잡한 로직으로 데이터를 요약하거나 가공할 때 익숙한 파이썬이 절실하다.
1
2
3
4
5
from pyspark import SparkContext
from pyspark.sql import SQLContext
sc = SparkContext.getOrCreate()
sqlContext = SQLContext(sc)
1
2
3
4
5
6
7
8
9
10
from pyspark.sql import functions as F
from pyspark.sql import Window
table = sqlContext.createDataFrame(
zip(
['A','B','A','B','A','B'],
['2020.06.01','2020.06.01','2020.06.02','2020.06.02','2020.06.03','2020.06.03'],
[100,1000,500,3000,1000,2000]
),
schema=['id','date','value'])
| id | date | value |
|---|---|---|
| A | 2020.06.01 | 100 |
| B | 2020.06.01 | 1000 |
| A | 2020.06.02 | 500 |
| B | 2020.06.02 | 3000 |
| A | 2020.06.03 | 1000 |
| B | 2020.06.03 | 2000 |
위와 같은 형태의 table이라는 이름의 데이터가 있다고 생각해보자. 각 id별로 시간의 흐름에 따른 value의 차분 값을 얻고 싶다고 가정해보자. 이것을 사용자 정의 함수를 사용하지 않고 순수하게 스파크의 함수들로만 해본다면 아래와 같다.
1
2
3
4
5
6
w = Window.partitionBy("id").orderBy("date")
table.withColumn("bef_value", F.lag("value").over(w)).dropna().\ # 1.
withColumn("diff_value", F.col("value")-F.col("bef_value")).\ # 2.
withColumn("array_value", F.collect_list("diff_value").over(w)).\ # 3.
groupby("id").agg(F.max("array_value").alias("value")).show() # 4.

id 별로 그룹지어서 date를 기준으로 정렬하여 이전 date의 value를 새로운 컬럼으로 만든다.
첫 value의 경우에 이전값이 없어서 null로 컬럼이 생기기 때문에 null 값이 있는 row를 제거해준다.
새로 생긴 이전 컬럼을 가지고 차분값을 연산한 새로운 컬럼(diff_value)을 만든다.
다시 id별로 그룹지어서 date를 기준으로 정렬하여 diff_value들을 collect_list 함수를 통해 묶어준다.
window 함수를 사용하여 컬럼을 만들었기 때문에 id 별로 가장 긴 row를 골라주는 작업을 수행
나의 짧은 지식 안에서는 groupby 함수를 사용해서는 특정 컬럼을 기준으로 데이터를 정렬하는 방법이 없다. 따라서 (3) / (4)번 과정과 같이 window 함수를 사용해서 date를 기준으로 정렬된 partition을 얻고, 그 안에서 collect_list 함수를 통해 value를 묶어주는 새로운 컬럼을 생성해줘야 한다. 그런데 이런 방식에서는 iterative하게 value들이 추가되는 방식으로 컬럼이 생성되기 때문에 그룹별로 가장 큰 리스트를 뽑아주는 작업이 한 번 더 필요하다.
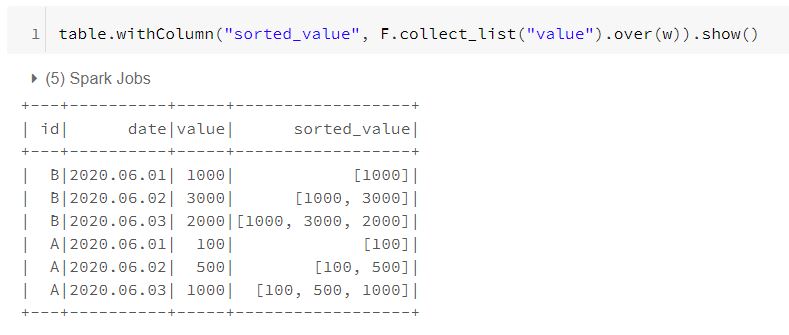
위와 같이 스파크 함수만을 사용하여 연산하는 방식이 효율적일지는 몰라도 남이 읽었을 때 조금 직관적이지 못한 것은 사실이다. 이것을 udf를 사용해서 수행해보면 아래와 같다.
1
2
3
4
5
6
7
8
9
10
11
from pyspark.sql.types import *
@udf(ArrayType(IntegerType()))
def sort_diff_value(date,value):
l = [x[1] for x in sorted(zip(date,value))]
return [a-b for a,b in zip(l[1:],l)]
table.groupby("id").agg(
F.collect_list("date").alias("date"),
F.collect_list("value").alias("value")).\
select("id", sort_diff_value(F.col("date"),F.col("value")).alias("value")).show()
PySpark는 기본적으로 UDAF(User Defined Aggregation Function)를 지원하지 않기 때문에 key가 되는 id 별로 값들을 하나의 row에 모아준 뒤에 row-wise하게 함수를 적용해줘야 한다. 따라서 이것 역시 함수 적용에 앞서 귀찮은 전처리 작업이 필요하다. 이런 어색함 없이, 직관적으로 group 단위의 함수 적용을 가능하게 만들어준 것이 Pandas UDF라고 보면된다.
Pandas UDF
참조: Introducing Pandas UDF for PySpark
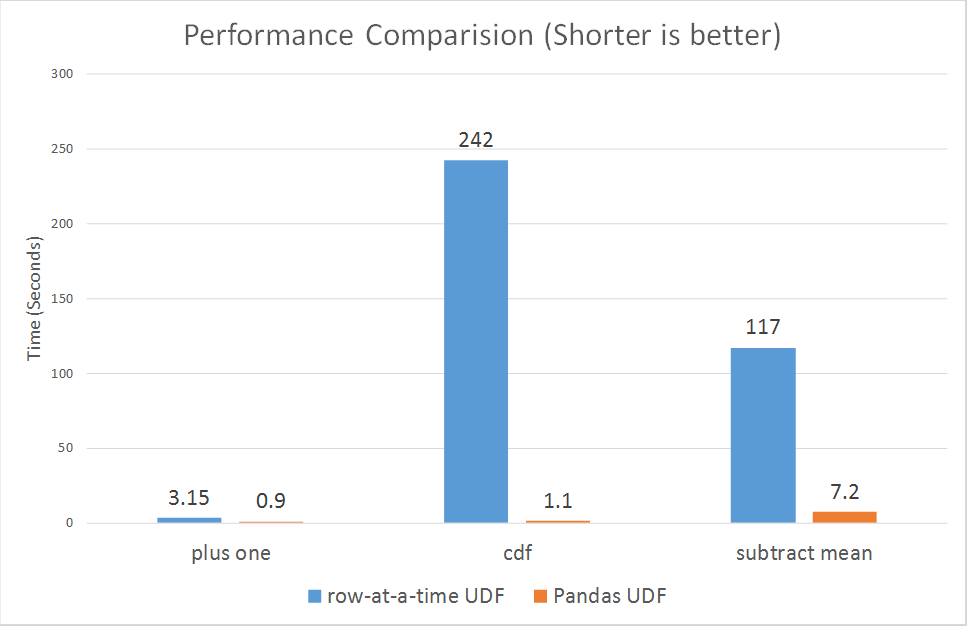
위의 예시에서 사용한 UDF 방식은 스파크에서 제공하는 Column-Based한 함수들에 대비하여 극도로 느리다. JVM memory에서 python이 읽을 수 있는 형태로 spark dataframe을 변환해주고, 다시 바꿔서 가져오는 과정이 추가되기 때문이다. 데이터를 온전히 파이썬이 처리해주다보니 Predicate pushdown, Constant folding와 같은 Spark 최적화 기법들의 수혜를 받지 못하게된다. 기존에는 이런 한계를 극복하기 위해 Spark의 native language인 Scala를 사용해서 UDF를 작성하는 노력이 필요했다.
Pandas UDF는 단순히 vectorized하게 함수를 적용해줄 수 있다는 장점 이외에도 Scala UDF만큼이나 빠르다는 장점이 있다. 왜 그런가를 알아보기 위해 Apache Arrow가 무엇인지 읽어보고 오자.
Apache Arrow
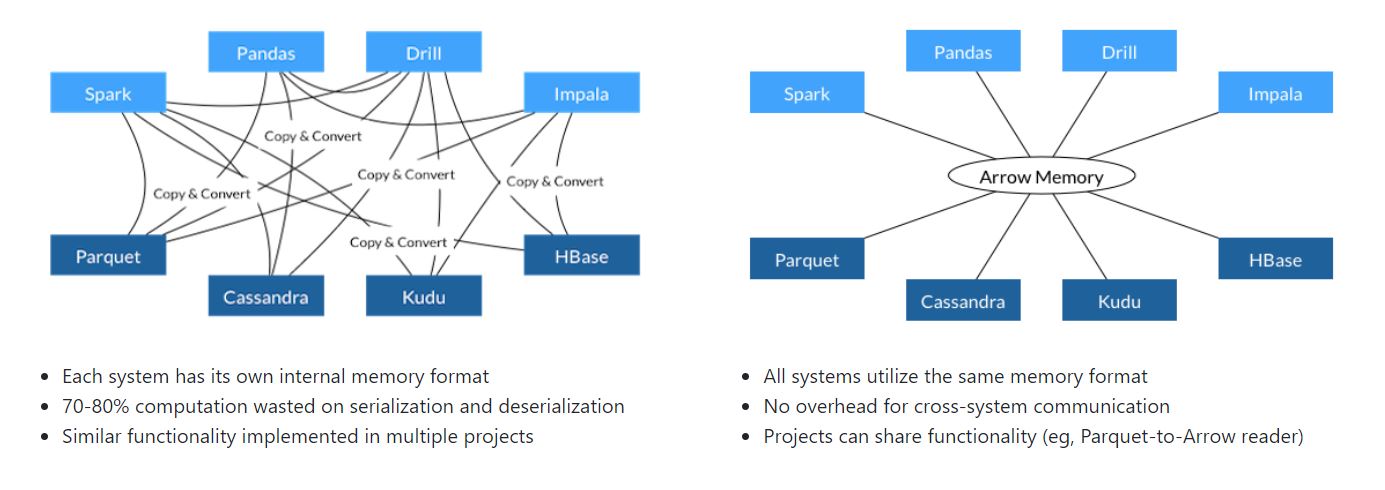
Apache Arrow is a cross-language development platform for in-memory data. It specifies a standardized language-independent columnar memory format for flat and hierarchical data, organized for efficient analytic operations on modern hardware. [Apache Arrow page]
사용하는 언어와 무관하게 컬럼 베이스하게 데이터를 효율적으로 처리할 수 있도록 도와주는 플랫폼이라고 한다. Apache Arrow가 in-memory columnar data format으로 언어와 시스템간의 데이터 포맷이 공유되는 것을 도와준다면, on-disk에서 이런 역할을 해주는 것은 Apche parquet이나 Apache ORC 등이 있다.
Apache Arrow는 스파크 버젼 2.3부터 통합되었으며 Pandas 형태의 인풋과 아웃풋으로 함수를 구성하는 Pandas UDF는 Apache Arrow가 제공하는 스파크와 Pandas 간의 데이터 포맷 공유 기능을 통해 빠른 연산 속도를 보장받게 된다.
본론으로 돌아와, Pandas UDF는 인풋과 아웃풋의 형태에 따라 3가지로 분류된다.
| Name | Input | Output |
|---|---|---|
| Scalar UDFs | pandas.Series | pandas.Series |
| Grouped Map UDFs | pandas.DataFrame | pandas.DataFrame |
| Grouped Aggregate UDFs | pandas.Series | scala |
Scalar UDFs
1
import pandas as pd # pandas udf이니깐 당연히 판다스를 불러와주고
우선 pd.Series에 함수를 적용하면 어떻게 되는지 확인해보자.
1
2
3
4
5
6
def squared(x):
return x*x
l = pd.Series([1,2,3])
squared(l)
# == pd.Series([1,4,9])
함수의 아웃풋은 1,4,9가 들어가있는 Series가 된다. 즉, Series의 원소에 iterative하게 함수가 적용된다.
1
2
3
4
5
6
7
8
9
10
11
12
@F.pandas_udf("long", F.PandasUDFType.SCALAR_ITER)
def plus_one(batch_iter): # yield를 사용
for x in batch_iter:
yield x + 1
def plus_one(batch_iter): # return을 사용
res = []
for x in batch_iter:
res.append(x + 1)
return res
table.select(plus_one(F.col("value")).alias("plus_one")).show()
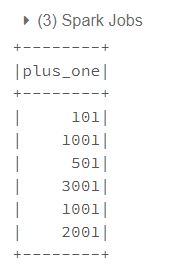
F.PandasUDFType.SCALAR_ITER는 Input으로 컬럼 길이 만큼의 iterator of batches를 받고 같은 길이의 batches를 yield하거나 iterator of batches를 return 할 수 있다.
1
2
3
4
5
6
@F.pandas_udf("string", F.PandasUDFType.SCALAR_ITER)
def concat_two_cols(batch_iter):
for a, b in batch_iter:
yield a.astype(str) + "__" + b.astype(str)
table.select(concat_two_cols(F.col("id"),F.col("value")).alias("concat_cols")).show()

두 컬럼을 넣어준 지금의 경우에는 pd.Series tuple 형태의 iterator가 함수의 input으로 들어간다. 그러나 Apache Arrow의 기능으로 속도가 높아졌다는 것 이외에 row-wise하게 함수가 적용되는 것은 기존의 UDF와 비교하여 큰 차이가 있어 보이지 않는다. 이어서, 기존의 UDF에는 불가능했던 데이터프레임을 함수의 Input으로 받는 UDF를 적용해보자.
Grouped Map UDFs
- Grouped Map UDF는 groupby( key ).apply( 사용자 정의 함수 )의 형태로 사용된다.
- 기존에 있던 컬럼에 함수를 맵핑 해주는 기능이기 때문에 기존 스키마의 Field name만 사용할 수 있다.
- 아웃풋은 DataFrame의 형태로. 키와 리턴해주는 모든 컬럼의 타입을 명시해줘야 한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
# 그룹별로 각 컬럼의 최대값과의 차이를 assign 해주는 함수
@F.pandas_udf("id string,date int,value int", F.PandasUDFType.GROUPED_MAP)
def diff_max(pdf):
d = pdf.date
v = pdf.value
return pdf.assign(
date = (pd.to_datetime(d.max()) - pd.to_datetime(d)).dt.days,
value = v.max()-v
)
table.groupby("id").apply(diff_max).show()
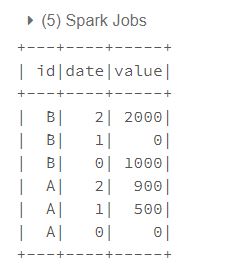
Grouped Map 작업의 경우 모든 테이블이 메모리에 올라간 후 함수가 적용되어
Spark의
maxRecordsPerBatch기능이 적용되지 않아그룹 별 사이즈가 매우 다를 경우memory exception을 일으킬 가능성이 크다고 한다.
Grouped aggregate UDFs
가장 자주 사용하게 되는 함수. 여러 컬럼을 동시에 집어넣은 후, 스파크 기본 문법으로는 참 귀찮고 어려운 알고리즘을 수행한 후 실수 형태의 서머리를 얻는 작업에 많이 사용된다.
- GROUPED_MAP과는 다르게 컬럼명 없이 return하는 결과물의 타입만 명시해주면 된다.
- 한 개 이상의 Series를 인풋으로 넣은 후 하나의 Scala 값을 얻는 작업에 수행된다.
각 id별로 시간의 흐름에 따른 value의 차분 값을 얻고 싶다.
따라서 key는 id가 되며 date와 value 두 Series가 인풋으로 필요하다.
1
2
3
4
5
6
@F.pandas_udf(ArrayType(IntegerType()), F.PandasUDFType.GROUPED_AGG)
def sorted_diff_value(date,value):
l = [x[1] for x in sorted(zip(date,value))]
return [aft-bef for bef,aft in zip(l,l[1:])]
table.groupby("id").agg(sorted_diff_value(F.col("date"),F.col("value"))).show()
함수의 형태는 기존 udf와 크게 다르지 않지만
- 그룹 별 데이터를 하나의 row에 몰아넣어 줄 필요가 없다는 점
- Apache Arrow의 유연한 in memory columnar data format을 사용할 수 있다는 장점이 있다.
오늘은 유연한 PySpark 프로그래밍을 위한 UDF의 활용, 그 중에서도 직관성과 최적화 측면에서 유리한 Pandas_UDF를 정리해봤다. 추후에는 조금 큰 데이터 / 복잡한 알고리즘을 사용하여, native spark language scala를 사용하여 작성한 Udf와 판다스 Udf를 비교해 보면 좋을 것 같다.