출처: Google Developers / Matrix Factorization
행렬 분해는 말그대로, 행렬을 분해하는 일이다. 어떤 행렬을 분해할까?
행렬 분해 기법은 추천 시스템을 구축할 때 자주 사용되는데, 추천의 대가 넷플릭스를 생각해보자.
넷플릭스에는 많은 유저(row)들이 있다. 넷플릭스에는 많은 영화(columns)들이 있다.
각 유저들은 각 영화를 봤을 수도, 혹은 보지 않았을 수도 있다.
위에서 서술한 상황을 행렬로 표현하면 아래와 같다.

이렇게 하나의 커다란 매트릭스를 분해하면 어떤 모습이 될까?
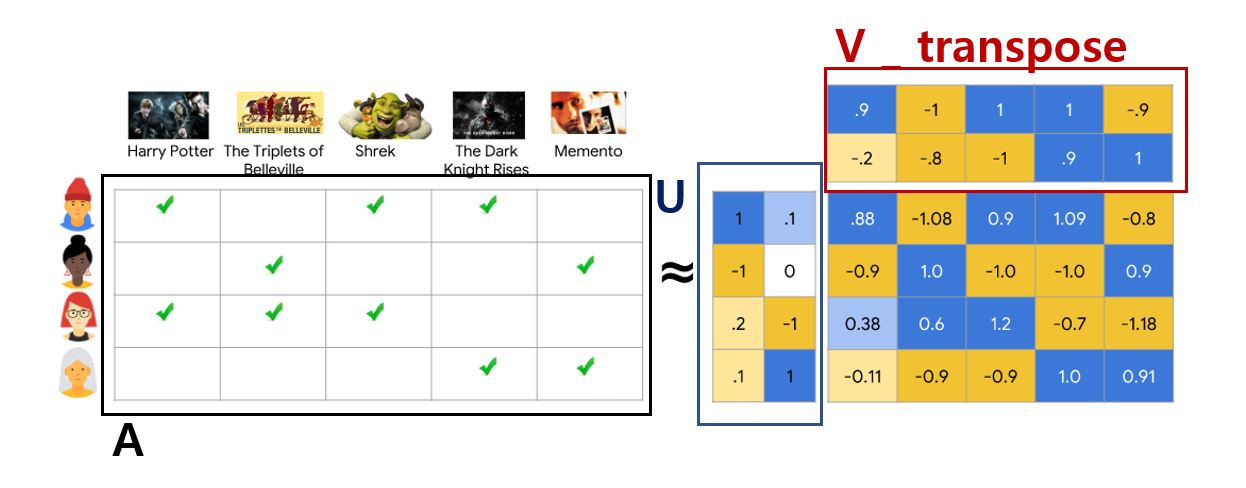
유저의 수와 동일한 row 개수를 갖는 파란색 매트릭스 U
영화의 수와 동일한 row 개수를 갖는 빨간색 매트릭스 V
매트릭스에 U에 V의 전치 행렬을 곱하면 원래의 검정색 매트릭스 A를 얻게 된다.
U와 V를 구하는 방법은 선형대수와 수치해석으로 나눌 수 있는데,
선형대수적인 방법은 주어진 행렬을 가지고 요리조리 만져서 U와 V를 짠하고 뽑아내는 것이고
수치해석적인 방법은 랜덤하게 U,V를 세팅해놓고 목적 함수를 줄여나가는 식으로 업데이트를 진행하는 것이다.
위 포스터에서는 3가지 목적함수를 제안한다.
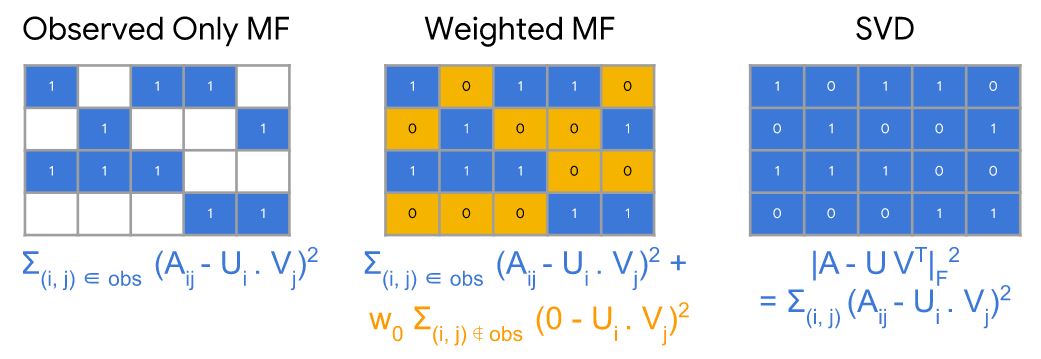
(1) Observed only MF:
- 유저가 실제로 본 영화들에 대해서 로스를 카운팅한다.
- 모든 Cell을 1로 예측하면 로스가 0으로 되서 분해된 행렬이 무의미해진다.
(2) Weighted MF:
- 유저가 실제로 본 영화들은 1로, 보지 않은 영화들은 0으로 나오도록 U,V를 유도한다.
(3) SVD:
- U와 V의 전치행렬이 곱해지면 기존의 매트릭스 A와 동일한 차원인 것을 차용