딥러닝을 서비스로 적용하기에는 많은 허들이 존재하는데, 주어진 문제가 너무 다양한 것도 그 중 하나이다. 많은 과제를 위한 많은 모델, 그리도 더더더 많은 모델의 계수를 관리하고 조정하는 것은 현실적이지 못하다. 회사에서 이상탐지를 위해 매일 아침 집계하고 모델링하는 시계열이 200만개쯤인데 이것들의 예측을 딥러닝을 사용하여 해보겠다는 것이 가당키나 할까?
딥러닝을 통한 시계열 이상탐지를 서비스화하기 위해서는 두 가지 조건이 있다.
(1) 좋은 예측을 위해 너무 많은 데이터가 필요하지 않을 것
(2) 다양한 시계열을 소수의 모델로도 관리할 수 있을 것
결국 필요한 것은 Few Shot Learning + Transfer Learning 인데
이 어려운 일을 해내는 것이 아래 논문에서 제안된 Learn to Learn 모델이다.
Few-Shot Learning
k-shot learning: 각 클래스 별, k개(1~5)의 데이터만으로 효과적인 분류가 가능하도록 하는 것
one shot learning: 클래스 별 하나밖에 데이터가 없는데 분류 모델을 수행
→ 사람에게 가능하니 모델도 할 수 있겠지!
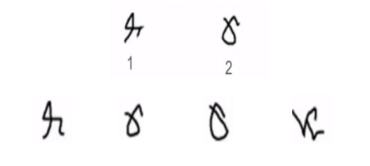
zero shot learning: 타겟 클래스에 대한 데이터가 전혀 없는채로 모델을 학습
- 말 클래스 & 색깔 클래스 두 가지 정보가 존재할 때,
얼룩말이라는 존재하지 않는 데이터를 모델이 학습할 수 있을까
- 말 클래스 & 색깔 클래스 두 가지 정보가 존재할 때,
Meta Learning: Learning to learn
Aim to train a model than can rapidly adapt to a new task with a few examples
= 적은 양의 데이터로부터, 새로운 task를 빠르게 학습할 수 있는 Meta Learner를 학습
= Few Shot Learning 학습을 잘 하기 위한 모델을 학습
Transfer Learning(pre-training) 접근법과는 어떻게 다를까?
Pre-Training은 일반적으로 재사용을 목적한다. 상위 layer의 파라미터는 고정하고 세세한 피쳐를 뽑아줄 것이라 기대하는 하위 layer만 업데이트한다. Manifold가 유사한 이미지에 대해 이미 학습이 선행되어 다른 데이터나 클래스 분류 과제로 이관이 가능할 것이라 믿는 것이다. 학습하는 방법을 학습하는 컨셉의 메타러닝과는 다르게 transfer learning은 선행 학습이라 볼 수 있다!
Abstract
모델에 무관한 meta-learning을 가능케 하는 알고리즘을 제안한다.
Meta Learning의 목표:
적은 샘플 트레이닝 데이터로도 새로운 과제를 잘 수행할 수 있도록 모델을 학습
메타 러닝을 통해, 모델의 parameter는 적은 데이터만으로도 효율적으로 업데이트된다
Introduction
사람은 빠르고 유연하게 새로운 것을 학습할 수 있고 특정 과제나 노력으로 국한되지 않는다.
MAML 모델은 Gradient Descent procedure로 학습되는 어떤 문제에도 적용 가능하다. 궁극적인 목표는 적은 데이터만으로 사람이 할 수 있는 일을 모델이 할 수 있도록 모델을 학습하는 것이다.
Initial Parameter가 몇 번의 업데이트 만으로 maximal performance를 발휘하도록 학습
기존의 연구들과는 달리, 특정 모델 구조에 한정적이거나 parameter를 늘리거나 하지 않는다
정리하자면 궁극적인 학습의 목적은 여러 과제에 범용적으로 적합하게 internal representation을 설정해 놓는 것이다. 최적의 포지션에 모델이 있다면 적은 데이터와 업데이트만으로도 좋은 결과를 얻을 것이라 기대할 수 있다. 다르게 말하자면 parameter의 관점에서 loss function의 sensitivity를 극대화하는 과정이라도 볼 수 있다.
Model Agnostic Meta-Learning
Meta learning Problem Set-Up
각 task가 하나의 원소가 되고, {task 집합}이 train set/test set이 된다

- Key Idea:
모든 task를 관통하는 distribution ‘P(t)’의 internal feature를 찾는다.
internal feature 중에서도 more transferable than others한 것들을 찾는다.
하나의 task에 over fitting하지 않고, 각 gradient step마다 여러 {sample task} loss를 줄인다.
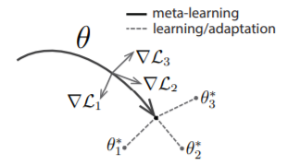
A Model-Agnostic Meta-Learning Algorithm
Task의 변화에 민감하게 반응하는 model parameter를 찾자!
기대하는 바
새로운 task가 P(t)와 같은 Space에 존재한다면 적은 update로도 좋은 성능을 발휘할 것
따라서 우리는 meta learner ‘f’ 를 찾는 것이 목표
새로운 i번째 task가 주어졌을 때, 모델은 우리가 일반적으로 알고있는 역전파의 형태로 학습된다
구체적인 학습 목표
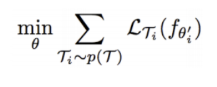

- MAML 알고리즘 학습 과정
{샘플 Task 집합}의 사이즈를 3이라 가정할 때
→ 전체 train 집합에서 T(1), T(2), T(3)를 샘플링한다
→ Initial Parameter θ를 저장
→ 각 T(i)에 대해 한 번(여러 번 가능)의 gradient update를 진행한 θ(i) 를 얻는다
→ θ(1),θ(2),θ(3)로 생긴 loss의 sum이 우리의 최종 loss
→ 최종 로스에 대해 back propagation을 하여 θ를 얻데이트 한다
→ 이 과정을 반복한다
주의할 것은 논문의 Loss가 multi-task learning(MTL)와 같다고 생각하면 안된다는 것이다.
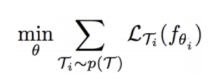
Multi-task learning loss
일반적으로 각 Task가 각자의 model을 갖고, shared layer에서 parameter를 공유하는 구조이다. MTL은 여러 task들을 동시에 학습하는 것이 각 task의 성능 향상에 도움을 줄 수 있다는 믿음이라 볼 수 있다. MTL의 장점은 regularization, knowledge의 공유되어 학습될 수 있는 것이다. 그러나, “주어진 모든 일을 잘 하도록 학습”되는 MTL의 컨셉은 “주어진 어떤 일에든 빠르게 적응하도록 학습”되는 MAML의 컨셉과는 다른점이 있다.
Species of MAML
해당 논문에서는 3가지 종류의 Task를 다룬다 (regression, classification, reinforcement learning). 컨셉은 모두 동일하고 loss만 task에 적합한 형태로 바뀌기 때문에 해당 리뷰에는 Regression만 다루도록 한다.
Supervised Regression
Goal
Similar statistical properties로 여러 함수들에 학습 되어 있을 때
새로운 함수의 #K data points만으로 다음 값을 잘 예측해보자.
LOSS

KEY IDEA:
-> 우리는 메타러너 ‘f’를 잘 만들어놨다.
-> 새로운 함수의 k개의 데이터 포인트를 알고 있다.
-> k data points로 f 를 gradient process한다.
-> f는 굉장히 loss sensitive한 상태이므로 k개로 충분히 좋은 모델로 진화한다.
Experimental Evaluation
Regression
P(t) = continuous sine wave
amplitude(높이) varies [0.1 ~ 5.0]
phase(넓이) varies [0, π]
‘f’ : 2 hidden layers of size 40 with ReLU
K-shot Learning (5개, 10개, 20개)
![]()
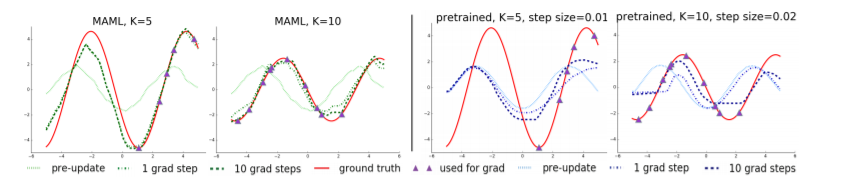
왼쪽 두 개는 MAML 한 것, 오른쪽은 Fine-tuning 한 것.
정리하자면 적은 데이터로, update로 타겟 함수의 phase & amplitude를 잘 잡아 낼 수 있다.
또한, Wave 절반의 데이터만으로 나머지 wave의 형태를 캐치한다.
meta learner ‘f’가 sine wave의 feature를 이미 알고 있기 때문이다.
Discussion and Future Work
논문에서 소개한 meta-learning 접근법은 모델이 굉장히 간단하고 미리 세팅해둬야 할 parameter가 없다. 따라서 gradient-based의 모든 task에 적용 가능하기 때문에 아주 활용성이 높을 것 같다. 수 많은 시계열을 단 몇 개의 모델로 관리할 수 있다면 얼마나 편할까. 그러나 모델에서 언급한대로 ‘f’는 similar statistical properties를 공유한 task에 대해서만 범용적인 적용이 가능하다. 따라서 해당 방법을 실제로 적용해본다면 주기성이 동일한 시계열끼리 묶고 각 군집마다 통용될 수 있는 ‘f’를 설계한 후 주기 길이만큼의 K points로 매일 매일 임시 모델을 업데이트하고 값을 계산하는 방식을 적용할 수 있지 않을까 싶다.