BERT
LSTM은 죽고 어텐션의 시대라고들 한다. 수 많은 Transformer의 파생 모델들 중에는 BERT가 제일이라고 한다. 오늘 리뷰하는 ELECTRA는 BERT의 파생이라고 볼 수 있다. 세세한 것들은 넘어가고 컨셉과 직관만으로 BERT를 살펴보자.
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
언어를 이해하기 위해 양방향의 정보를 종합했다. 어떻게? 트랜스포머의 구조를 사용해서.
수능 영어 빈칸 문제를 푸는 많은 스킬들은 우선 빈칸의 앞뒤 문장을 빠르게 훝는 것에서 출발했다. 문맥에 맞는 어휘를 선택하는 일은 문장의 앞과 뒤 양쪽의 정보를 모두 고려하지 않고서는 불가능하다. 따라서 기존의 트랜스포머가 → 방향의 Language Modeling을 수행하는 것은 반쪽짜리 일을 했다고 볼 수 있다. 이런 부분을 보완하기 위해서 ELMo와 같은 논문에서는 → ← 방향을 독립적으로 따로따로 학습시킨 다음 마지막에 정보를 종합하는 방식의 모델 구조를 가졌다. 그런데 ELMo와 같은 컨셉이면서 훨씬 간단한 구조로 모델을 학습시키는 방법이 BERT를 통해 제안됬다.
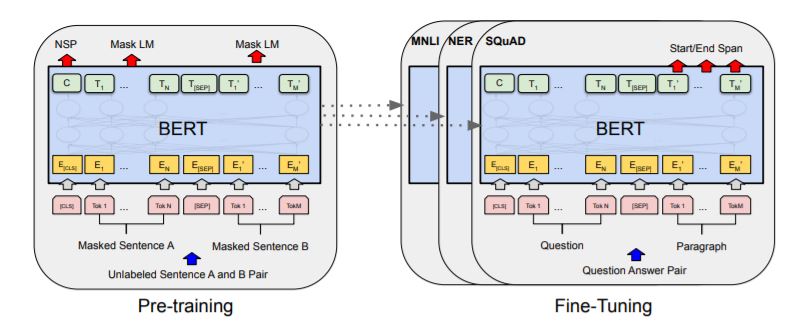
버트의 학습 과정은 (1) Pre-Training, (2) Fine-Tuning 두 과정으로 나누어진다. 모델의 구조와 parameter 수는 그대로 유지한 채, 해결하는 과제만 바꾸는 것인데, 우선 pre-training을 보자.
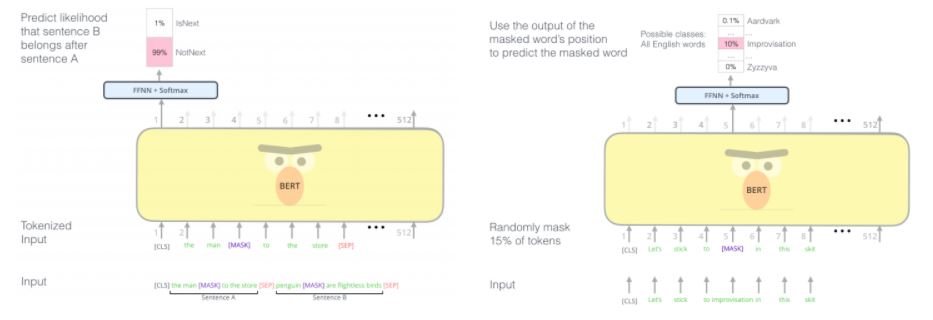
BERT는 빈칸 맞추기, 어색한 문장 찾기. 두 가지 과제를 해결하며 Pre-Training한다.
Task #1: Masked LM
나는 xxxx을 점심에 먹었다를 Input으로 모델에 넣어나는 치킨을 점심에 먹었다를 Ouput으로 내놓도록 만든다.
조금 구체적으로. Input 중간 중간의 단어를 [MASK] 라는 토큰으로 치환한 후에 Self-Attention Layer에 태운다. [MASK] 토큰이 문장의 모든 단어에게 영향을 받으며 임베딩되기 때문에 bidirectional한 정보가 담긴 아웃풋을 가지게 된다. 이런 Masked Language Modeling(MLM) 방식의 학습 전략은 뒤에 ELECTRA에서도 다시 언급되기 때문에 기억해두자. 또한 이런 방식의 전략은 오토인코더와도 유사하다고 볼 수 있지만, BERT는 오직 MASK 된 인덱스에서만 Loss를 계산한다는 차이점이 있다.
그러나 Fine-Tuning 과정에서는 [MASK]라는 토큰이 불필요할 수 있다. 따라서 로스 계산을 위해 지정되는 15%정의 Index 중에서 80% 정도만 마스크 토큰으로 치환하고, 10%는 랜덤, 10%는 그대로 인풋에 넣는다고 한다.
예를들어, Input이 단어 200개의 문장이라고 생각하면, Input과 Ouput의 다름을 계산하는 것은 전체 중 30개의 단어뿐이다. 그런데 30개의 단어를 모두 [MASK] 라는 단어로 바꾸는 것이 아니라, 3개 정도는 치킨 -> 피자 같이 랜덤하게 바꾸고, 3개 정도는 치킨 그대로 Input에 넣어주어 학습을 수행한다.
Task #2: Next Sentence Prediction (NSP)
Fine-Tuning의 목적이 되는 많은 과제들은 Question Answering (QA) and Natural Language Inference (NLI)와 같이 여러 문장을 인풋으로 받게 된다. 따라서 Task 1과 같이 문장 내에서 적절한 어휘를 선택하는 과제뿐만 아니라 여러 문장간의 관계를 학습하는 전략도 필요하다. BERT에서 Pre-Training에 적용한 NSP는 두 문장을 넣어준 뒤, 두 문장이 문맥적으로 이어지는 관계인지 Y/N으로 판단하는 과제이다.
그런데 Output Layer의 어느 부분에서 Y/N 판단을 수행할지가 애매하기 때문에 모든 Input의 앞에 [CLS]라는 토큰을 붙여주기로 정했다. 또한 두 문장의 중간에는 [SEP]라는 토큰을 껴주기로 정했다.
나는 점심으로 치킨을 먹었다. 간식으로는 아이스크림을 먹었다.
위의 두 문장이 연결되는지 판단하는 과제를 해결하기 위해서 Input을 아래와 같이 넣어준다.
[CLS] 나는 점심으로 치킨을 먹었다. [SEP] 간식으로는 아이스크림을 먹었다.
그리고 마지막 Output Layer에서 [CLS] 토큰의 index에 튀어나온 벡터에 FC Layer를 조금 붙여 Y/N을 얻는다.
이외에 여러 실험적인 부분들은 패스하고 오늘 리뷰하고자 하는 ELECTRA로 넘어가보자.
ELECTRA
ELECTRA 역시 BERT 구조의 모델을 특정 Task를 통해 Pre-Training하고 이후에 상황에 맞게 Fine-Tuning한다. Bert 이후에 수 많은 연구자들이 어떻게 최소한의 비용으로 Bert의 전략을 수행할 수 있을까 고민해왔는데, 구글에서 얼마전 발표한 ELECTRA가 많이들 흥미로운 모양이다.
ELECTRA: PRE-TRAINING TEXT ENCODERS AS DISCRIMINATORS RATHER THAN GENERATORS
PRE-TRAINING 텍스트 인코더를 만들거다. 그런데 생성기가 아니라 분류기를 사용할거다.
일반적으로 BERT의 학습 전략 중 MLM은 [MASK] 라는 위치의 토큰에 어울리는 단어를 생성하는 Generator라고 볼 수 있다. 그리고 많은 연구들은 어떻게 Generator를 빠르고 똑똑하게 학습시킬지 고민해왔다. 그런데 이런 방식의 학습 전략은 전체 문장에서 [MASK] 토큰을 덧씌울 15% 정도의 단어에서만 Loss를 얻는다. 직관적으로도 이것이 데이터를 완벽하게 소화하지 못하는 학습방법으로 느껴진다. ELECTRA는 Generator 뒤에 Discriminator라는 모듈을 덧붙여 모든 Input에서 Loss를 창출하는 방법을 제안했다.
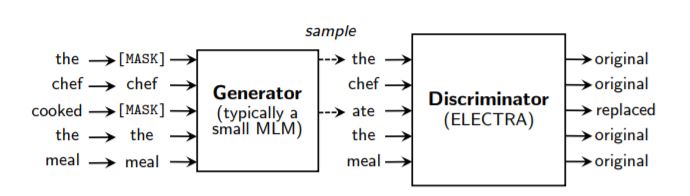
Generator
the chef cooked the meal이라는 문장에서 일부 단어를 마스킹한 뒤, 그 위치의 단어를 생성한다.
Discriminator
Generator가 생성한 새로운 문장을 인풋으로 받아서, 각 단어가 원래 Input과 동일한 것인지 체크한다.
문장에서 각 단어가 어색한지 혹슨 정상인지 분류하는 과제를 수행한다고도 볼 수 있다.
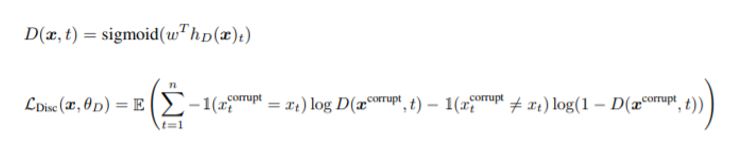
만약 X_corrupt (Generator가 생성한 값)가 원래의 X_t와 동일하다면 D(x, t)의 값이 1에 수렴해야 한다.
ELECTRA의 학습 전략은 Generator가 noise를 인풋으로 받아 Disciminator를 속일 수 있는 Output을 생성하며 똑똑해지고, Disciminator가 Generator의 생성 여부를 판단하며 똑똑해지는 과정을 반복하는 GAN과 유사하게 보이기도 한다. 그러나 ELECTRA가 GAN과 다른 세 가지 부분이 있는데,
- ELECTRA는 진짜 혹은 가짜를 구별하는 것이 아니라 정답 혹은 오답을 구별한다.
- Generator가 Discriminator를 얼마나 속였는지를 학습 목표로 삼는 Adversarially training 기법을 사용하지 않고 input을 잘 복원하는 maximum likelihood를 사용했다. Electra의 경우 masking index가 sampling되어 생성되기 때문에 학습 과정에서 adversarial loss를 사용하여 back-propogate하는데 어려움이 있다.
- Generator가 인풋으로 noise를 받지 않는다.
Weight Sharing
결국에 Fine-Tuning을 진행할 때에는 전체 Electra에서 Generator 부분은 버리고 Discriminator 부분만 학습시킬 것이다. 그런데 Generator와 Discriminator의 parameter를 완전히 따로 업데이트한다고 생각하면, 기존의 BERT 모델과 대비하여 두 배나 커다란 모델을 학습한다고 볼 수 있다.
따라서 두 모듈이 같은 parameter를 공유하는 weight sharing 기법을 사용하게 된다. 논문에서는 generator의 크기를 discriminator와 대비하여 작게 만드는 것을 권유하기 때문에 embedding layer의 parameter를 공유하는 것을 제안한다.
이렇게 효율적인 학습을 위해 Parameter를 재사용하는 컨셉의 Weight Sharing이 마냥 새롭지는 않다. 이전에 오토인코더 모델의 구조를 봤을 때에도 Decoder Layer를 Encoder Layer와 완벽하게 동일하게 사용하여 학습 파라미터의 수를 절반으로 줄인다는 글은 많이 봤던것으로 기억한다.
그런데 구체적으로 어떻게 Weight Sharing이 기법이 적용되는가에 대해서는 쉽게 이해가지 않는다.
Input - Layer 1 - Layer 2 - Layer 3 - Layer 1 - Output
위의 구조로 모델을 설계했을 때 내부적으로 어떻게 Layer 1의 파라미터는 업데이트 되는 것일까?
- 두 Layer 중 하나의 층을 Freeze하고 업데이트가 완료된 후에 복사하는 것일까?
- 아니면 서로 다른 두 Loss에 대해 두 번 업데이트가 이뤄지는 것일까?
Pytorch Tutorial을 통해 같은 Layer를 여러번 반복했을 때 무슨 일이 일어나는지 확인해보자
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
import torch
class SimpleNet(torch.nn.Module):
def __init__(self, D_in, H, D_out):
super(SimpleNet, self).__init__()
self.input_linear = torch.nn.Linear(D_in, H)
self.middle_linear = torch.nn.Linear(H, H)
self.output_linear = torch.nn.Linear(H, D_out)
def forward(self, x):
h_relu = self.input_linear(x).clamp(min=0)
h_relu = self.middle_linear(h_relu).clamp(min=0)
y_pred = self.output_linear(h_relu)
return y_pred
class DynamicNet(torch.nn.Module):
def __init__(self, D_in, H, D_out):
super(DynamicNet, self).__init__()
self.input_linear = torch.nn.Linear(D_in, H)
self.middle_linear = torch.nn.Linear(H, H)
self.output_linear = torch.nn.Linear(H, D_out)
def forward(self, x):
h_relu = self.input_linear(x).clamp(min=0)
for _ in range(3):
h_relu = self.middle_linear(h_relu).clamp(min=0)
y_pred = self.output_linear(h_relu)
return y_pred
DynamicNet은 한 번 Input이 들어가서 input layer - 3겹의 middle layer - output layer를 거친다.
동일한 크기의 로스가 발생한다면
SimpleNet과DynamicNet이 다르게 업데이트 될까?
1
2
3
4
5
6
7
8
9
10
N, D_in, H, D_out = 64, 1000, 100, 10
# 입력과 출력을 저장하기 위해 무작위 값을 갖는 Tensor를 생성합니다.
x = torch.randn(N, D_in)
y = torch.randn(N, D_out)
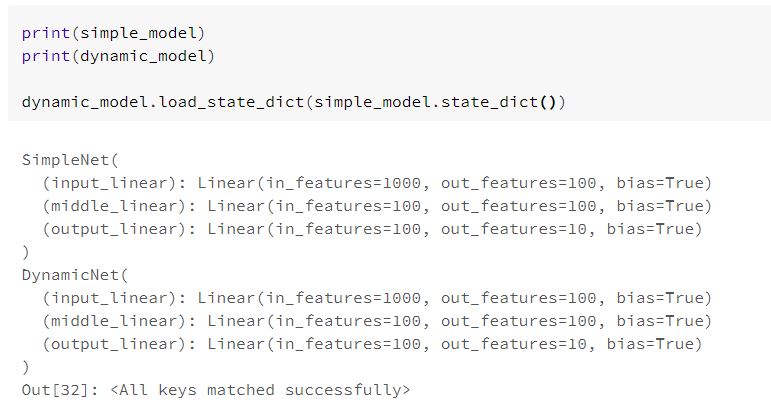
simple_model = SimpleNet(D_in, H, D_out)
dynamic_model = SimpleNet(D_in, H, D_out)
criterion = torch.nn.MSELoss(reduction='sum')
가상의 Input, Output을 생성하고 업데이트 방식과 모델을 정의한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
pred = simple_model(x)
for t in [simple_model, dynamic_model]:
y_pred = t(x)
y_pred.data = pred.data
loss = criterion(y_pred, y)
optimizer = torch.optim.SGD(t.parameters(), lr=1e-1, momentum=0.9)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(list(t.middle_linear.parameters())[0][0][:5])
middle_linear layer의 수에 따라서 loss가 다르게 나오기 때문에 기존 model로 고정된 loss를 생성
prediction output은 각 모델에 종속적이라서 prediction data만 골라서 복사해주는 방식이 아니라, simple_model의 output을 dynamic_model의 backward에 사용하면 에러가 발생한다.

- 같은 크기의 loss에 대하여 middle layer의 파라미터가 다르게 업데이트 됬음
- 즉 pytorch 내부적으로는 middle layer가 3번 업데이트를 수행하였다고 추측됨
- 그렇다면 weight sharing을 수행한다는 것은 그렇지 않은 모델과 단순히 복잡성이 다른게 아니라 학습의 방향도 다르게 될 것 같은데, 문제는 없을까??
Smaller Generator
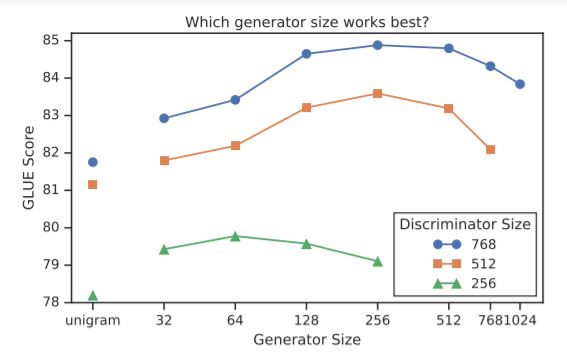
- 가로축이 Generator의 Size.
- Discriminator의 경우 size를 높일수록 성능이 명백하게 높다.
- 그러나 Generator의 경우는 오히려 더 작은 사이즈일 때 스코어가 더 높게 나타나는 경우도 있다.