Databricks

회사에 와서 낯설게 느껴졌던 것 중 하나는 업무의 많은 부분이 Databricks라는 환경에서 이루어진다는 것이었다. 사실 반년을 넘게 사용했지만 아직도 기능 많고 효율적이고 공유 가능한 쥬피터 노트북 정도로 느껴질 때가 많다. 사실 Databricks가 워낙 거대한 플랫폼이고 너무너무 많은 기능을 제공해주기 때문에, Databricks란 무엇인가?와 같은 뜬구름 잡는 포스트는 쓰고 싶지 않다. 업무를 하다가 가끔 아오 왜 이런게 안되지? 우와 이렇게 하면 되네? 와 같은 것들을 하나하나 꿀팁마냥 기록해나가보려고 한다.
위키피디아에 그냥 써있는 대로 보자면, Databricks는 아파치 스파크 프로젝트 중 일부이며, Scala 언어로 만들어진 오픈 소스 분산 컴퓨팅 프레임워크이다. 홈페이지 메인의 설명을 보면 데이터의 수집부터 처리 분석부터 모델까지, 데이터를 활용한 모든 파이프라인을 관리할 수 있는 플랫폼이라 보면 되는 것 같다.
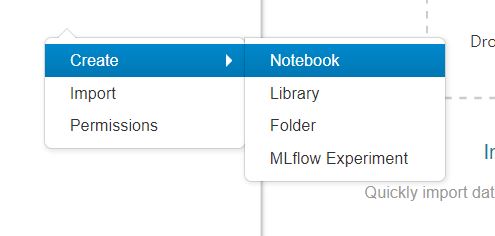
모든 구조와 요소들을 모두 이해할 필요는 없겠지. 나의 역할은 잘 가공해주신 데이터를 의미있게 활용하는 것이다. 클라우드가 뭔지 잘 몰라서 이렇게 말해도 되는지 잘 모르겠지만, 내가 속해있는 데이터 브릭스의 클라우드 환경에는 각자의 업무 공간이 존재한다. 권한만 주어진다면 서로의 코드를 재사용하는 것도, 수정하는 것도, 실행하는 것도 모두 자유롭게 가능하다. ./home/치오니 폴더/치오니 노트북 이라는 경로에 어떤 파이썬 함수를 내가 만들어놓으면 누구나 자신의 공간에서 이 함수를 사용하는 것이 가능하다.
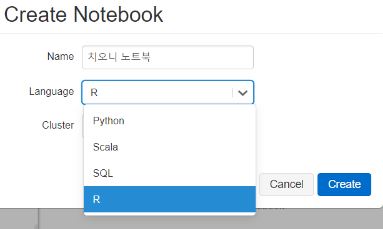
각 노트북에는 두 가지 선택해줄 부분이 있는데, 하나는 (1)어떤 언어를 기반으로한 노트북을 생성할 것인지와 (2)어떤 클러스터의 리소스를 사용할 것인지이다. 공부해보고 싶은 것 중 하나가 클러스터의 리소스와 용량에 관한 것들인데 그건 나중에 보기로 하고 노트북을 어떻게 사용하는지를 살펴보자.
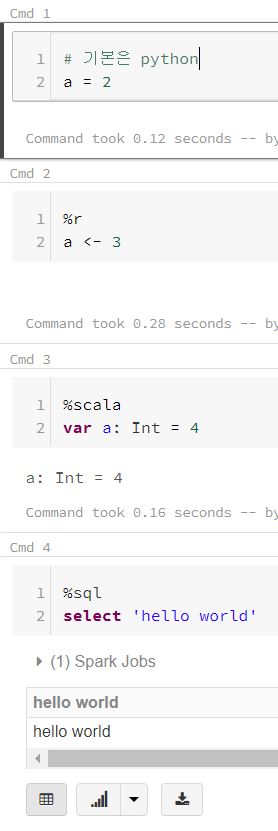
기반 언어를 python 으로 설정했다고 하여 다른 언어를 사용하지 못하는 것은 아니다. %사용하려는 언어를 놓고 해당 문법을 사용해서 셀을 실행할 수 있다. 그리고 %를 사용하여 %md (마크다운) %sh (쉘)의 명령어를 내리는 것도 가능하다. %sh pip install torch 등과 같은 코드를 사용하여 클러스터에 등록되어 있지 않던 라이브러리를 다운로드하는 것도 할 수 있다.
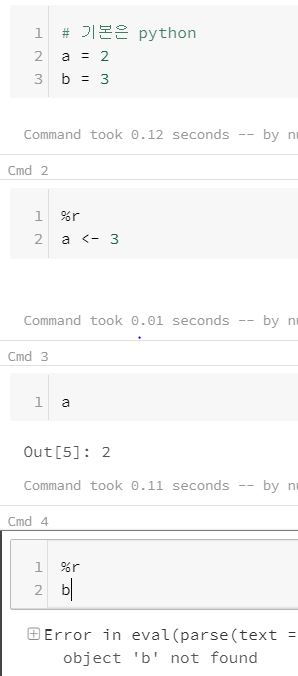
그러나 상상한 것 보다 이런 노트북 환경이 유용하지 않은 경우가 많았다. 위의 이미지와 같이 다른 언어를 사용하여 파이썬으로 할당해놓은 변수를 사용하는 것도, 할당된 변수를 덮어쓰기 하는 것도 불가능하기 때문이다. 이런 환경은 가공과 모델링을 다른 노트북에 쪼개서 수행하고 시각화하는 부분만 r의 ggplot을 사용하고 싶은 니즈가 있을 때 매우 귀찮다. 이런 작업을 수행하기 위해서는 작업의 중간중간 과정의 테이블들을 DB에 저장해놓고 꺼내쓰는 수고가 필요하다.
Dbutil

그래도 이런 연결되는 작업들을 조금 수월하게 할 수 있게 도와주는 dbutil이라는 기능이 databricks에 있다. 여러 태스크를 유연하게 연결하고 데이터베이스를 효율적으로 관리하고 파라미터나 시크릿 키 등을 재사용하기 위한 기능이라고 한다. dbutil은 용도에 따라 5가지로 구분할 수 있다.
File system utilities
- Databricks File System(DBFS)에 접근하고 조회하기 주로 사용
Notebook workflow utilities
- 여러 노트북의 작업들을 run & exit method를 활용하여 연결된 체인처럼 사용
- run에는 path / timeout / argument를 넣을 수 있다.
- timeout을 통해 시간안에 완료되지 않았을 때의 exception 수행
- 해당 노트북에서 사용하는 값들을 argument에 key-value 형태로 집어넣을 수 있다.
- exit를 통해서는 teomporary view 생성 / dbfs에 데이터 쓰기 / json 리턴 등이 가능하다.
- 아래서 자세히 봐보자.
Widget utilities
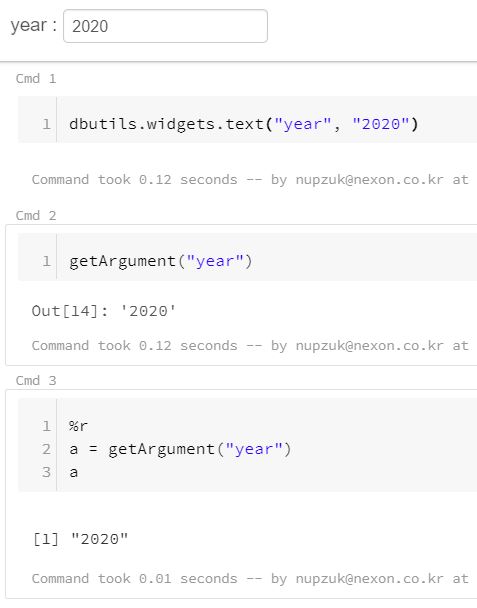
반응형의 widget을 생성하여 자주 사용하는 변수들을 여러 언어의 cell에서 재사용할 수 있다.
getArgumen(변수 명)을 통해 할당해놓은 값들을 다시 사용해준다.

상단에 위젯이 등장하고 여러 언어의 셀에서 사용한다
Secrets utilities
- 비밀로 해야할 변수들은 jdbc에 저장해놓고 dbutils.secreat.get()으로 가져와 주자
Library utilities
%sh pip install torch 와 같이 셀을 shell로 바꾸고 명령을 수행해줘도 되지만
dbutils.library.installPyPI(“torch”)의 형태로 라이브러리를 받을 수도 있다.
Notebook Workflow
dbutils에 어떤 기능들이 있는지 가볍게 살펴봤으니, 원래의 취지에 맞게 여러 노트북을 연결해서 작업하기를 수행해보자. 사용하게 될 dbutils의 클래스는 dbutils.notebook이다. 아쉽게도 dbutil에서 exit를 통해 무언가를 전달할 수 있는 기능은 python과 scala에만 지원하고 있다. 따라서 R 노트북을 사용하는 일은 SparkR을 리뷰할 때로 미룬다.
프로젝트에 사용되는 노트북은 총 3개이다.
- 데이터를 가공하기 위해 사용되는 1_Handling
- 가공된 데이터를 모델링하기 위해 사용되는 2_Modeling
- 모델링한 결과물을 시각화하기 위해 사용되는 3_Drawing
가공하고, 모델링하고, 시각화하는 일련의 작업들을 여러 노트북으로 쪼개어 관리해보자.
1_Handling
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
from pyspark.sql.types import *
from sklearn import datasets
import pandas as pd
iris = datasets.load_iris()
iris = pd.concat([
pd.DataFrame(iris['data']).\
apply(lambda col: (col - min(col))/(max(col) - min(col))),
pd.DataFrame(iris['target'], columns = ['label'])], axis = 1)
irisSchema = StructType([ StructField("v1", FloatType(), True),\
StructField("v2", FloatType(), True),\
StructField("v3", FloatType(), True),\
StructField("v4", FloatType(), True),\
StructField("label", IntegerType(), True)])
spark.createDataFrame(iris, schema=irisSchema).createOrReplaceGlobalTempView("iris_handling")
아이리스 데이터를 불러와서 각 컬럼을 min-max 정규화해주고, 가공된 데이터를 스파크 데이터프레임으로 변환한 후 createOrReplaceGlobalTempView라는 기능을 통해 “iris_handling” 이라는 이름을 가진 테이블을 임시로 생성해준다.
2_Modeling
1
dbutils.notebook.run("1_Handling", 60)
모델링 노트북은 핸들링 뒤에 연쇄적으로 이루어지기 때문에 맨 앞에서 1번 노트북을 실행해준다.
1
2
3
4
5
6
7
8
9
10
11
12
13
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
import json
global_temp_db = spark.conf.get("spark.sql.globalTempDatabase")
iris = table(global_temp_db + "." + "iris_handling").toPandas()
X_train, X_test, y_train, y_test = train_test_split(iris.loc[:,["v1","v2","v3","v4"]], iris.loc[:,'label'], random_state=0)
knn = KNeighborsClassifier(n_neighbors=1)
knn.fit(X_train, y_train)
print("Test set score (knn.score): {:.2f}".format(knn.score(X_test, y_test)))
위의 노트북에서 temporary view에서 저장해줬기 때문에 스파크의 globalTempDatabase에 iris_handling이라는 테이블이 존재한다. 위의 코드는 아주 간단한 knn 기법을 통해 모델링을 수행해 준 것이고 테스트 셋에 대한 정확도는 0.97이 나왔다.
1
2
3
4
5
6
7
8
9
10
output = {1:[], 0:[]}
pred = knn.predict(X_test)
answ = list(y_test)
for idx,y in enumerate(X_test.index):
if pred[idx] == list(y_test)[idx]: output[1].append(X_test.loc[y,:].tolist())
else: output[0].append(X_test.loc[y,:].tolist())
dbutils.notebook.exit(json.dumps(output))
output은 knn모델의 예측 결과물이 맞은 경우에는 output[1]에 변수들의 리스트가 저장되고, 틀린 경우에는 output[0]에 변수들의 리스트가 저장된다. 그림 그리기에 사용할 노트북에 데이터를 전달해줘야하기 때문에 2_Modeling 노트북을 나가면서는 output과 함께 exit 해준다. json.dumps는 딕셔너리 형태의 데이터를 json 형식의 스트링으로 치환해주는 함수이다. 즉, dubtils.notebook.exit은 노트북의 종료와 함께 하나의 스트링을 전달할 수 있는 기능이다.
3_Drawing
1
output = dbutils.notebook.run("2_Modeling", 60)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
import json
import pandas as pd
import matplotlib.pyplot as plt
output = json.loads(output)
fig, ax = plt.subplots(nrows=4, ncols=4, figsize=(10,10))
def drawing(i,j):
cmap = {0: 'red', 1: 'blue', 2: 'yellow', 'x':'black'}
data = output['1']
data = pd.DataFrame([[x[0]] + [x[1][y] for y in [i,j]] for x in data], columns = ['label',i,j])
data.loc[len(data)] = ['x'] + [output['0'][0][2][y] for y in [i,j]]
data = data.loc[:,~data.columns.duplicated()]
return data.plot(kind='scatter', x=i, y=j, color = data.label.map(cmap), ax = ax[i,j])
for i in range(4):
for j in range(4):
drawing(i,j)
display(plt.show())
3번 노트북에서는 DB에 임시로 저장된 테이블을 사용하는 방식이 아니라 2번 노트북에서 내뱉는 스트링을 사용해주기 때문에 run과 동시에 output에 exit 결과물을 할당해준다. 모델링의 결과물을 보면 37개의 테스트 데이터 중에 딱 하나의 결과물만 맞추지 못했다. 어떤 변수가 특이해서 이렇게 잘 못된 결과물을 내뱉었을까? 변수를 두 개씩 묶어서 scatter plot을 그려보고 검은색으로 오답 데이터를 씌어보자.
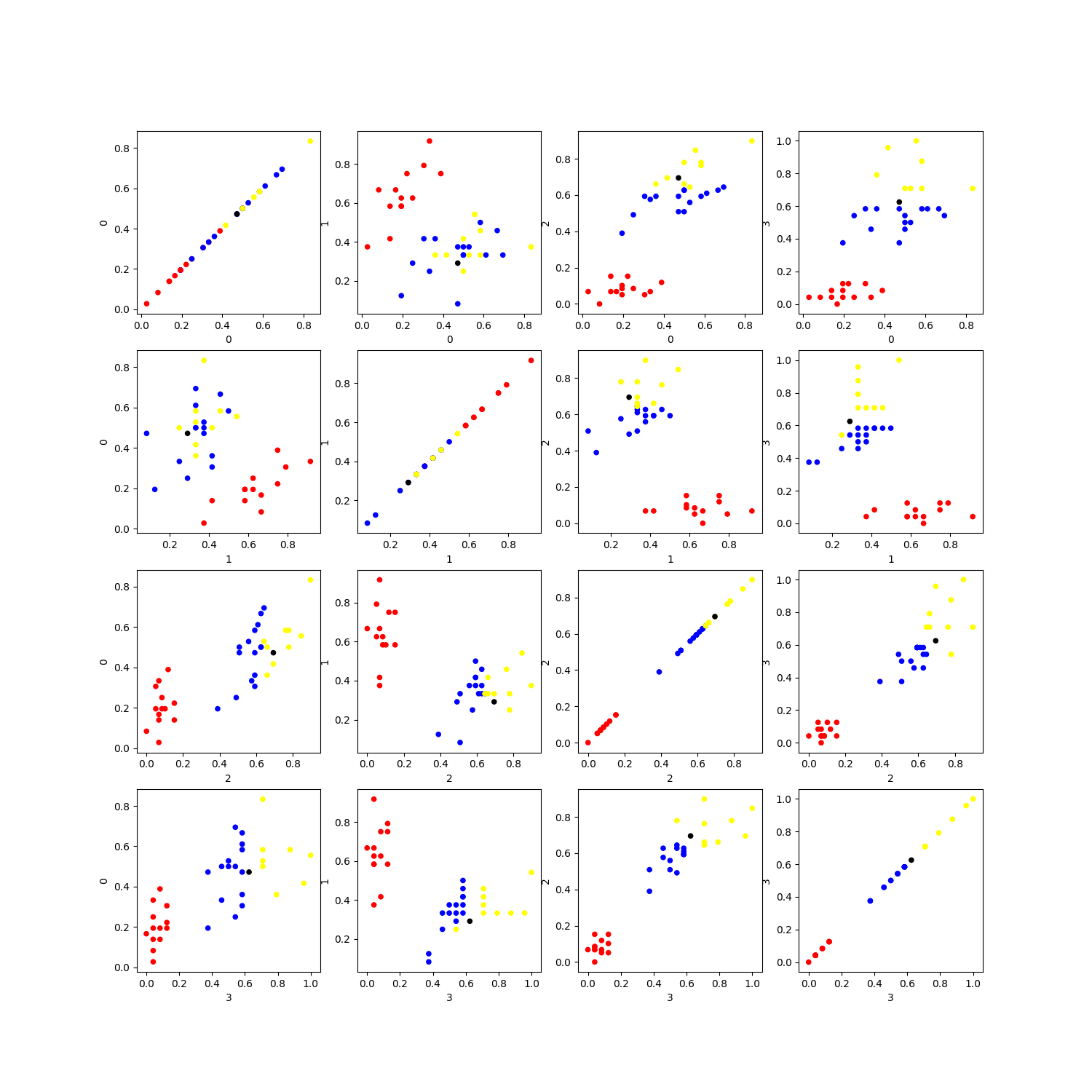
답은 1(blue), 예측은 2(yellow)
꿈보다는 해몽이지만, 전체 그래프의 (3,3) subplot을 봐보면 변수 2에 대해 오답 데이터가 yellow에 많이 쏠려있는 것을 볼 수 있다. 그래서 틀렸나보다?
여러 노트북을 연결해서 작업할 수 있는 dbutil의 기능을 사용해보았다. 모든 작업을 모듈화해서 하나의 main 노트북에서 돌리는 방식이 조금 더 일반적일 수도 있지만 분업의 관점에서는 dbutil의 기능을 활용하는게 더 좋을 수 있을 것 같다고 개인적으로 생각한다.